Appearance
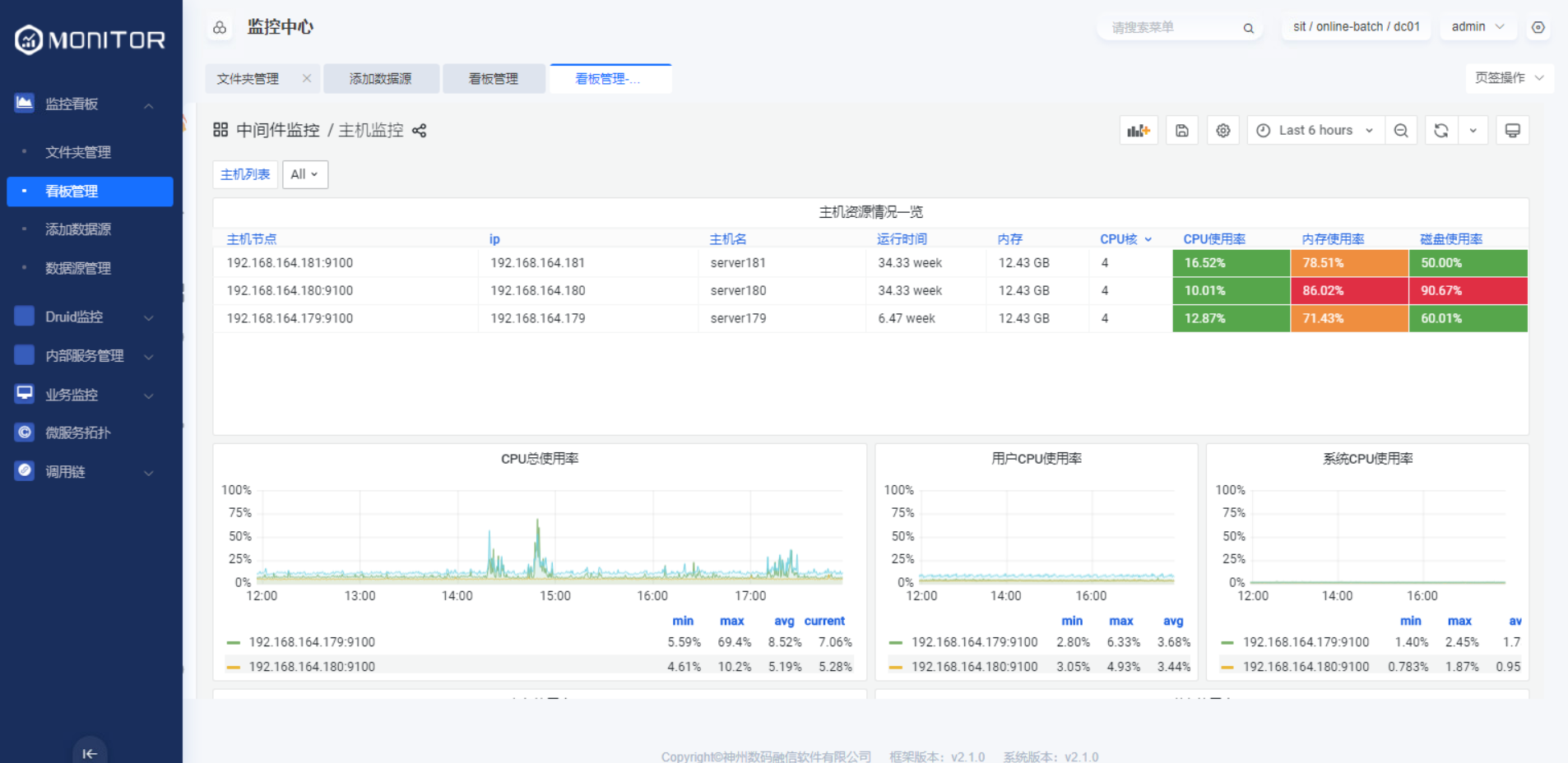
监控中心
1.1.Druid监控
1.1.1.数据库基本信息
该菜单为添加oracle表空间监控所需要的oracle管理员用户。
数据库基本信息添加
添加具有读取oracle数据库连接数、表空间等参数权限的用户。
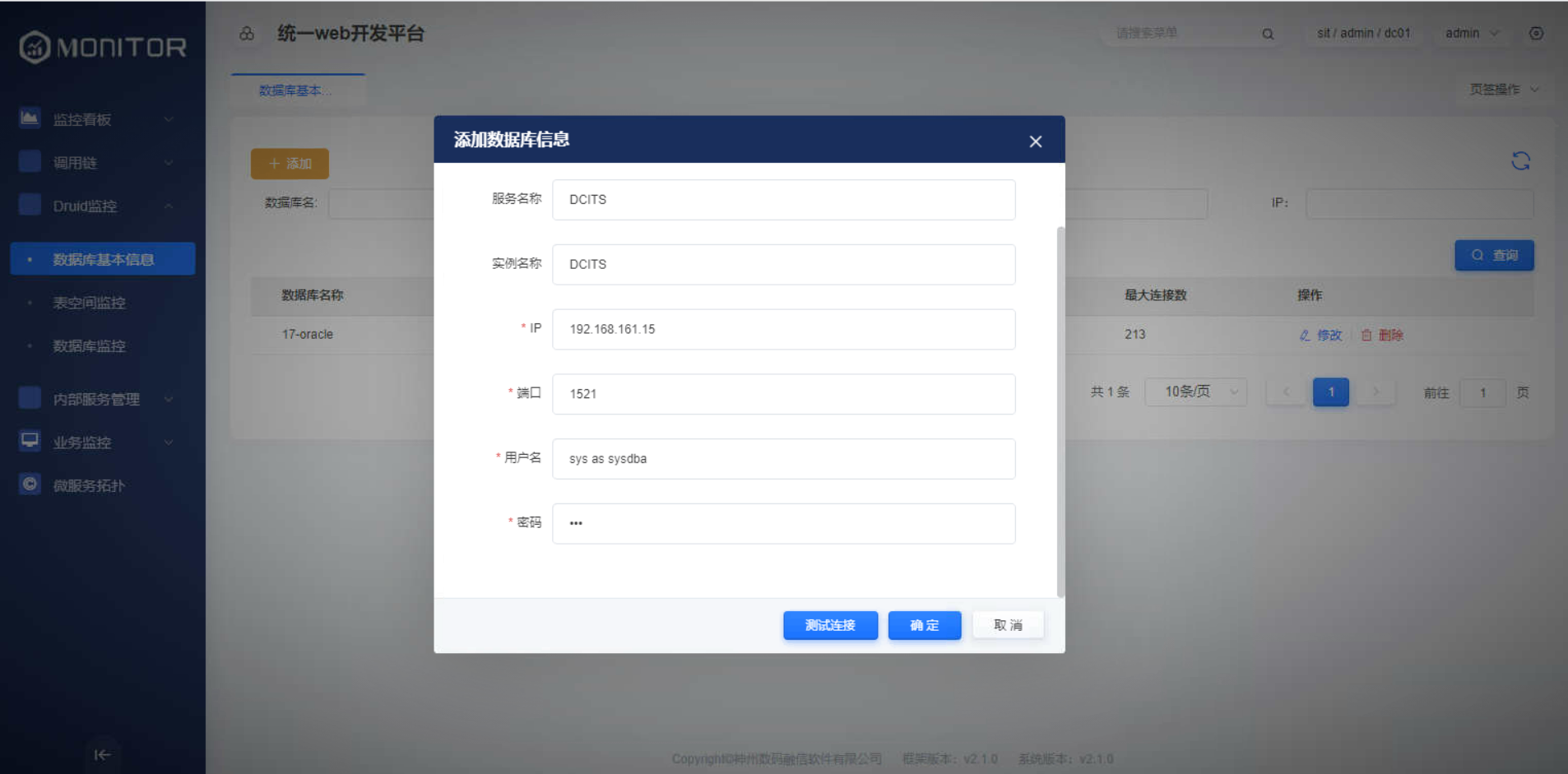
数据库基本信息列表

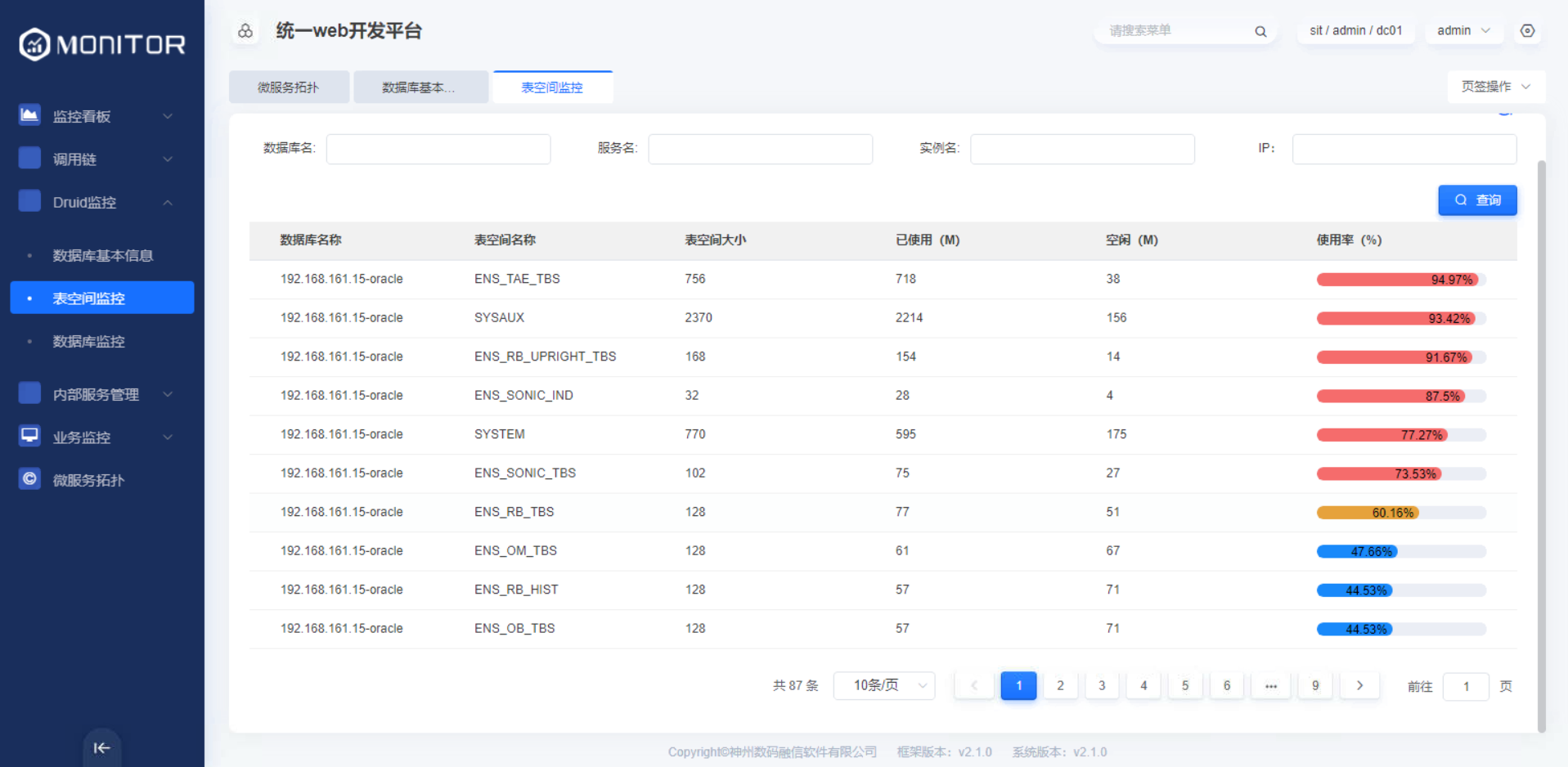
1.1.2.表空间监控
该菜单提供基于某个数据库连接下的表空间名称、表空间大小、表空间使用率等的监控。
1.1.3.数据库监控
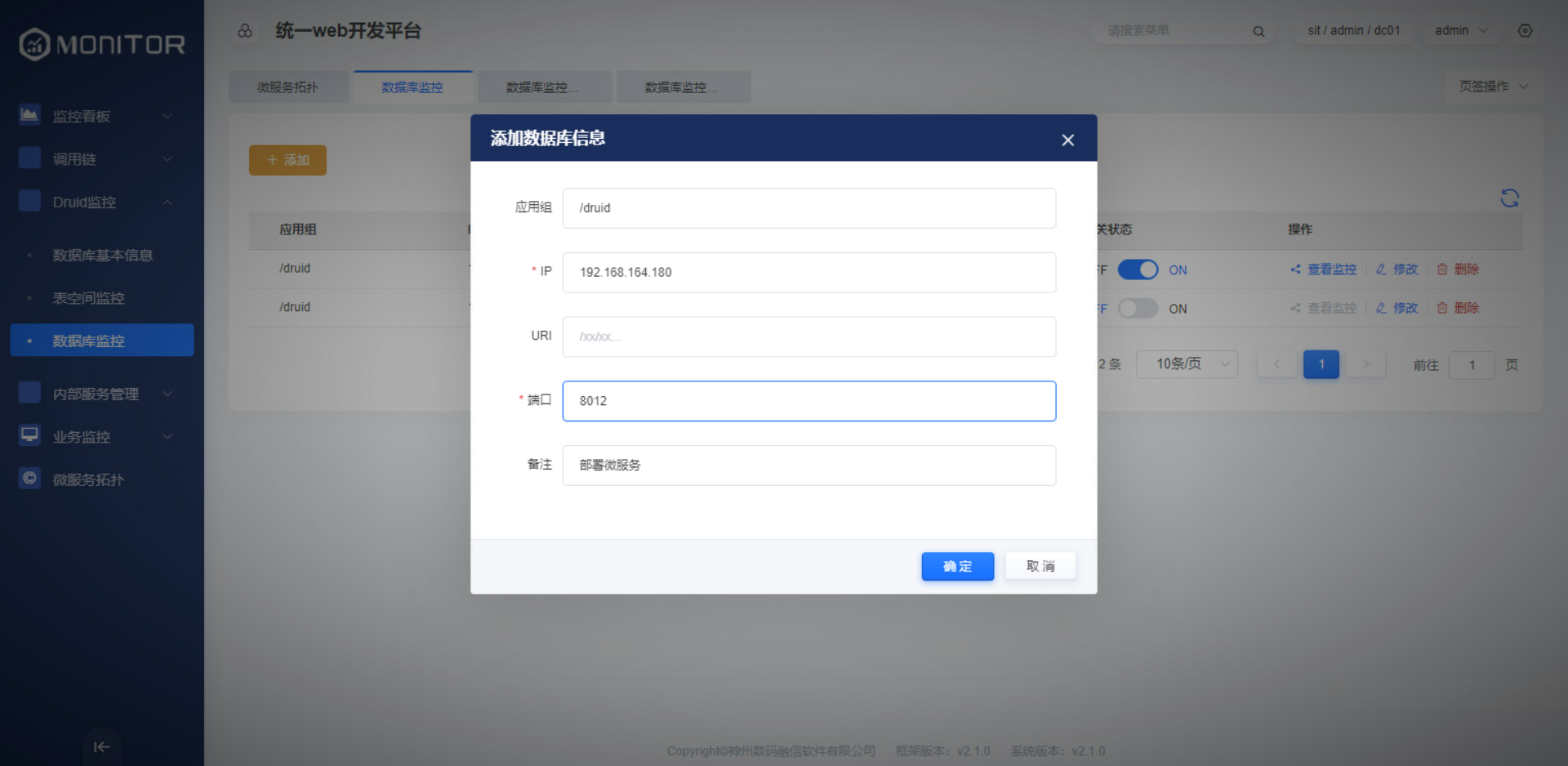
添加druid监控的相关信息。
应用组默认为:/druid,当更改druid原始监控目录后,该应用组也需要同步修改。
IP:监控某应用实例节点所在的IP地址
端口:监控某应用实例节点的端口
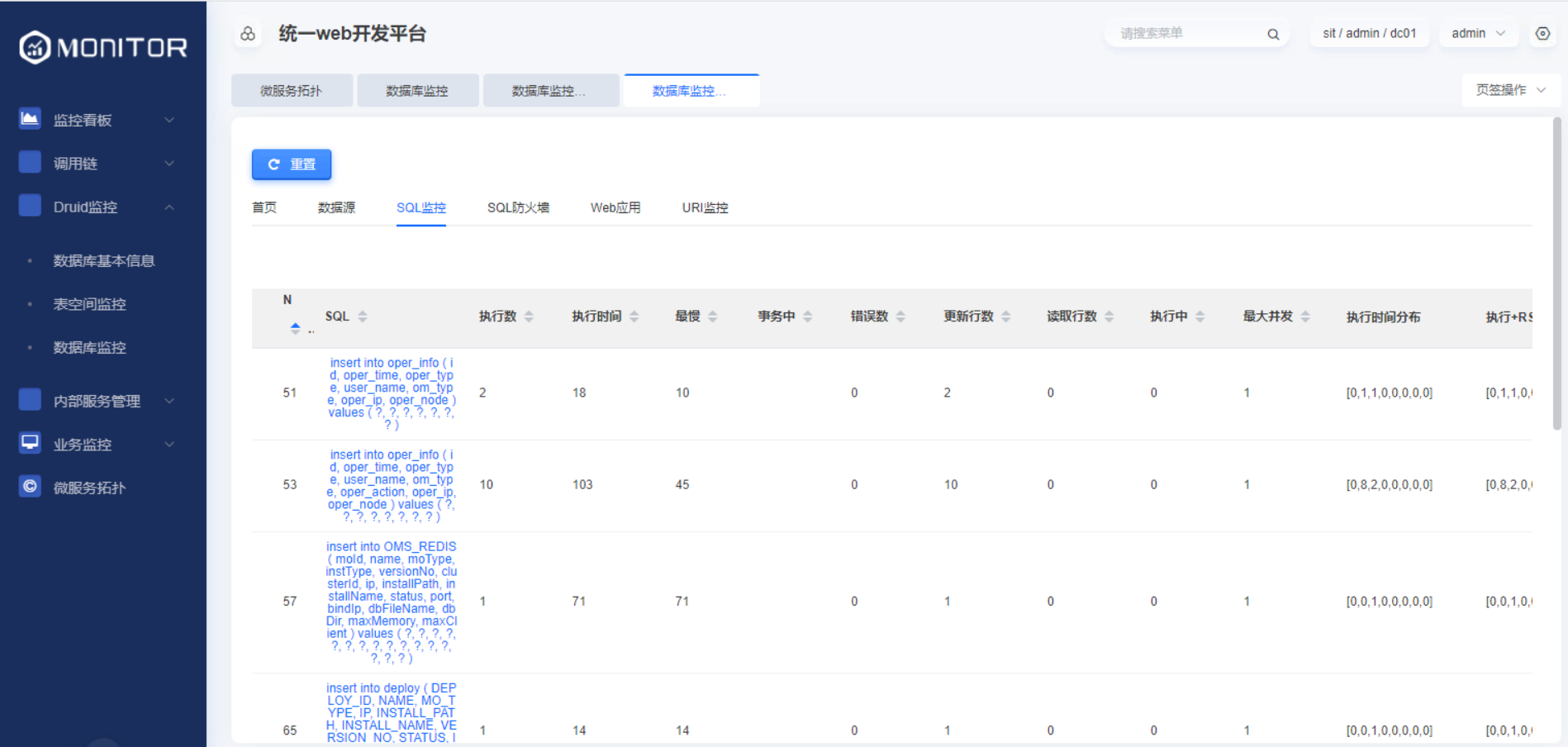
1.1.4.重要配置:
druid监控数据使用druid原生提供的接口采集,需要所监控应用的druid配置相关filter,并且去掉其鉴权配置。否则采集不到。
yaml
spring:
datasource:
druid:
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙
filters: stat,config,wall
#通过connectProperties属性来打开mergeSql功能;慢SQL记录
connection-properties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
#以下为基于spring boot web的内嵌druid监控,若需开启请将三个值均置为true
stat-view-servlet:
enabled: true
allow:
web-stat-filter:
enabled: true1.1.5.可能遇到的问题
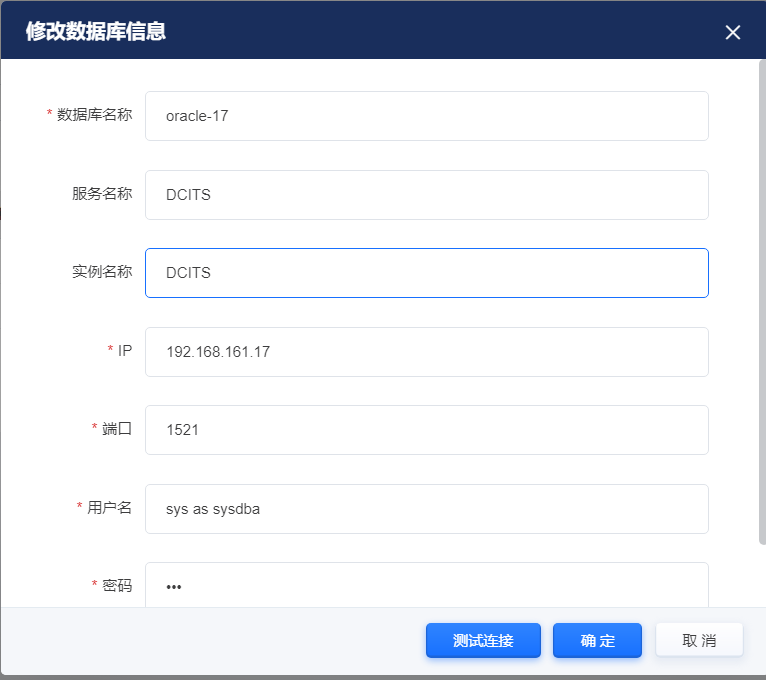
1.添加数据库后,表空间中没有数据
解决办法:oracle数据库的话,确定是否使用的管理员账号登录,注意用户名的格式为:${user} as sysdba,,下图为例:
2.Druid监控-查看监控中,没有数据
解决办法:查看是否按照上述对druid监控配置,若已配置,查看服务是否使用了libra,若两个都存在,则druid监控将无法运行
1.2.调用链
1.2.1.集成skywalking
在application-${profile}.yml文件中配置skywalking地址
skywalking:
url: http://dcits.cbs.skywalking.dev1:8080
监控中心使用RPC远程调用skywalking服务端的方式实现调用链。
当访问调用链时会跳转到monitor的SkywalkController,分别调用queryServices、queryServiceTopo、queryTopoInfo方法,在方法内将json拼接,使用restTemplate.postForEntity方法发到skywalkingServerURL,使用skywalking的原生方法。
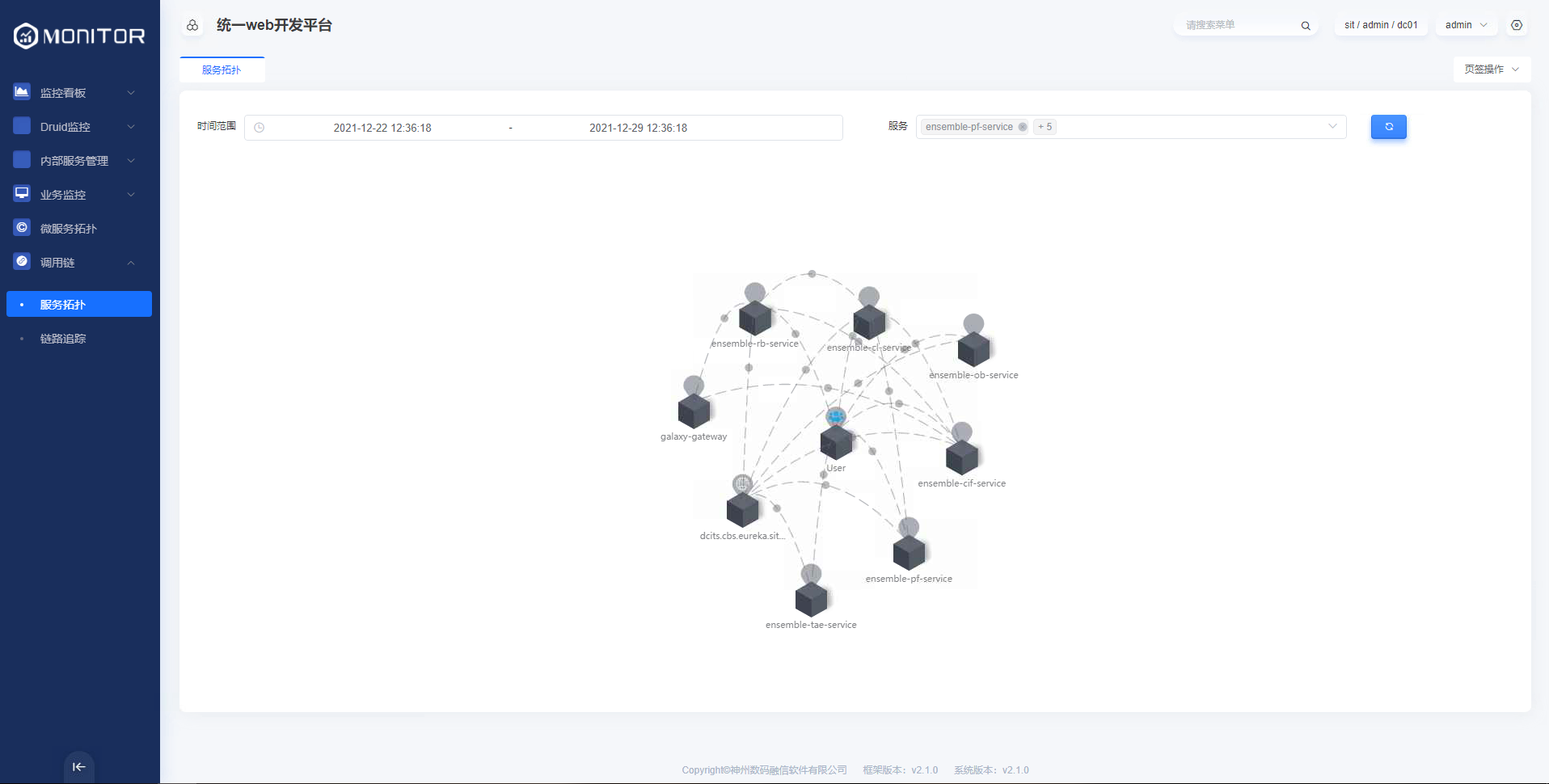
1.2.2.服务拓扑
查询某些微服务某段时间服务之间的调用关系、每分钟请求量及延时。
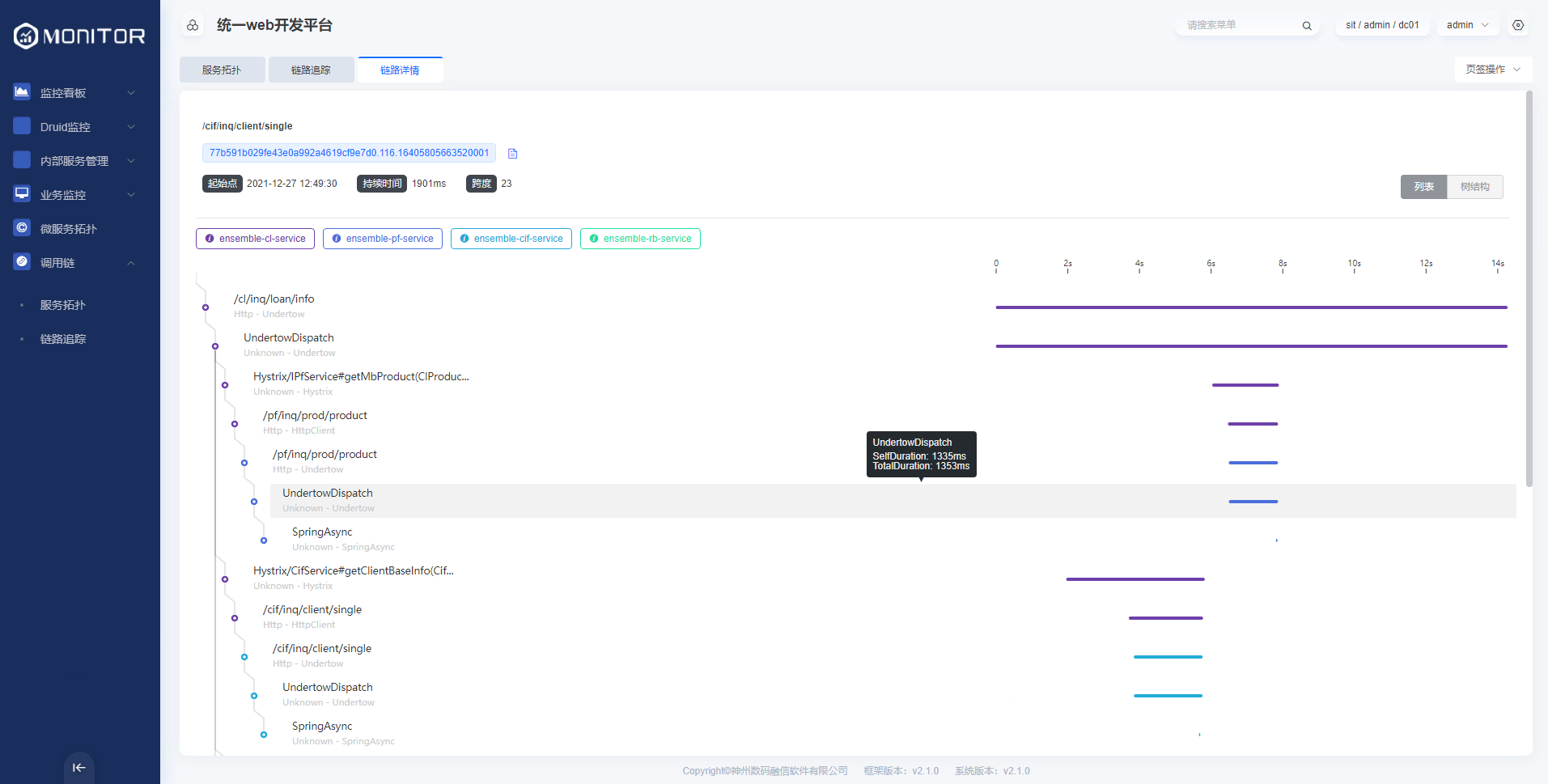
1.2.3.链路追踪
根据服务、实例、端点、链路ID、状态、排序、等参数查询某段时间内服务的调用链路。

链路详细信息
1.2.4.重要配置:
应用自身需要参考《08-调用链skywalking》集成相应的javaagent。
1.3.监控看板
1.3.1.数据源管理
目前通过从eureka上拉取各微服务应用的actuator端点上获取的线程数、堆内存、非堆内存等数据存储到Influxdb时序数据库中。
调用链等数据存储在elasticsearch中。
如果搭建了Prometheus服务,可添加Prometheus数据源。
在influxdb中oms_monitor存储微服务的线程数、堆内存、非堆内存等监控数据。
aries-monitor微服务通过http://aries-monitor微服务IP:aries-monitor微服务port/applications接口获取Eureka注册中心上的微服务列表及微服务暴露的 http://微服务IP:微服务port/actuator/metrics端点,从metric端点上获取微服务的系统监控数据,并且存储到influxdb的oms_monitor数据库中。
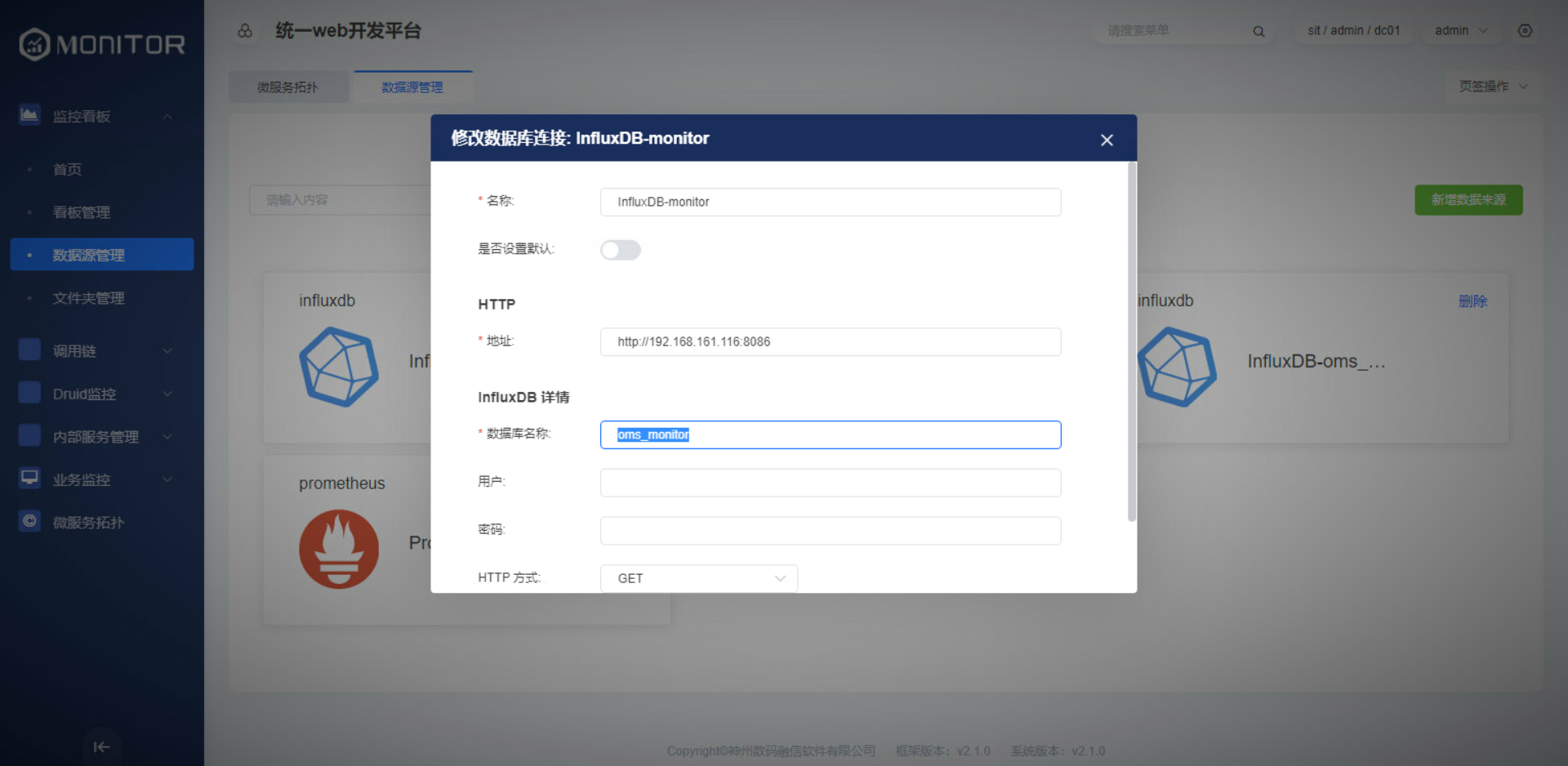
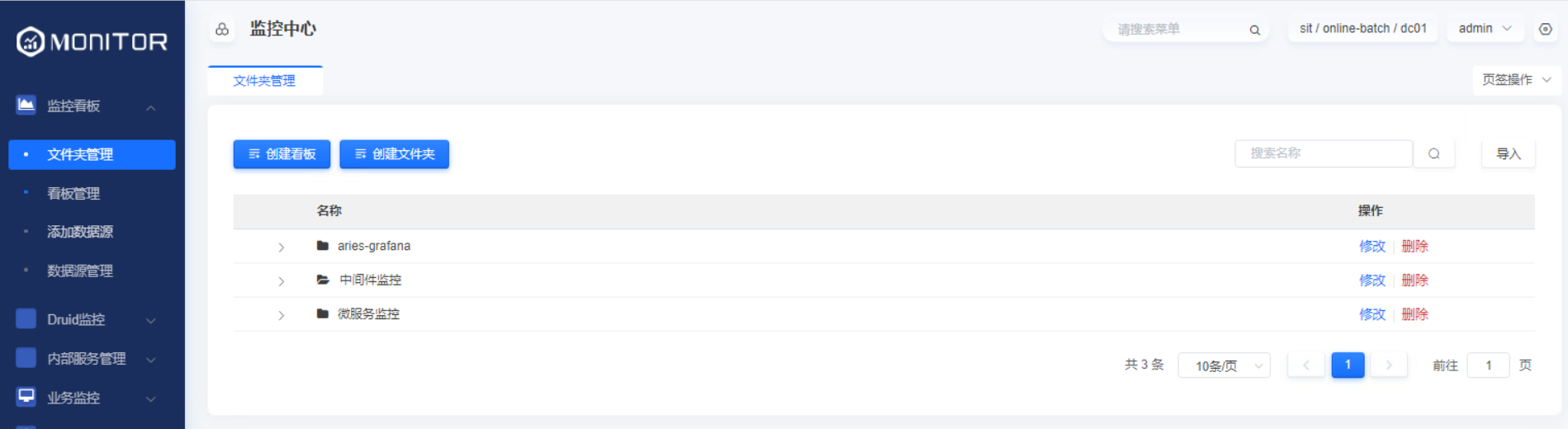
1.3.2.文件夹管理
创建监控看板的文件夹,用来存储对应的看板文件,看板数据存储到grafana-server的sqllite数据文件中。

从标准版本获取到的dashboards.zip看板文件依次导入。保证看板名称、看板的Uid不重复,选择监控指标使用的数据源oms_monitor导入即可。
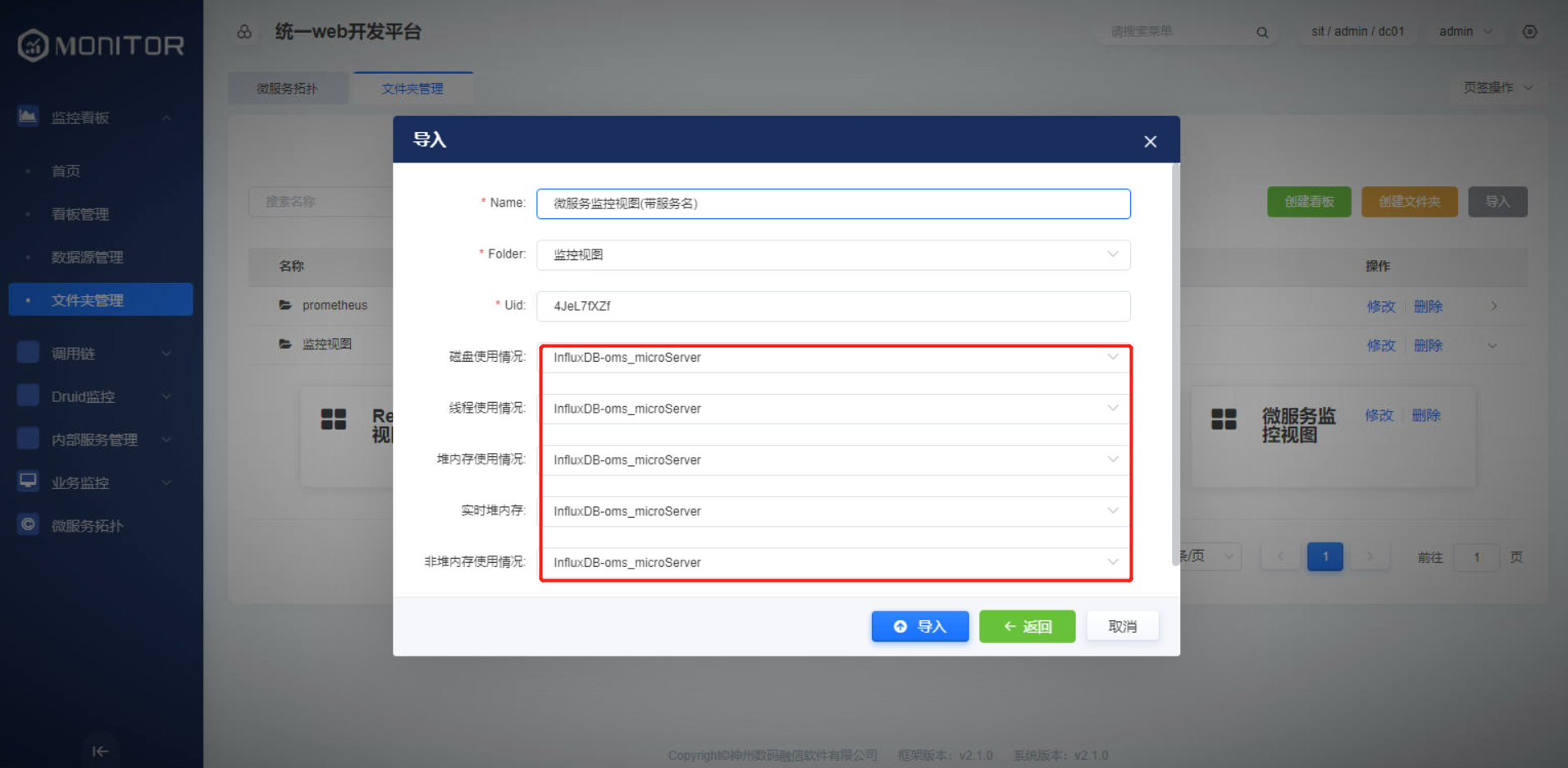
导入json看板文件后设置真实的数据源。
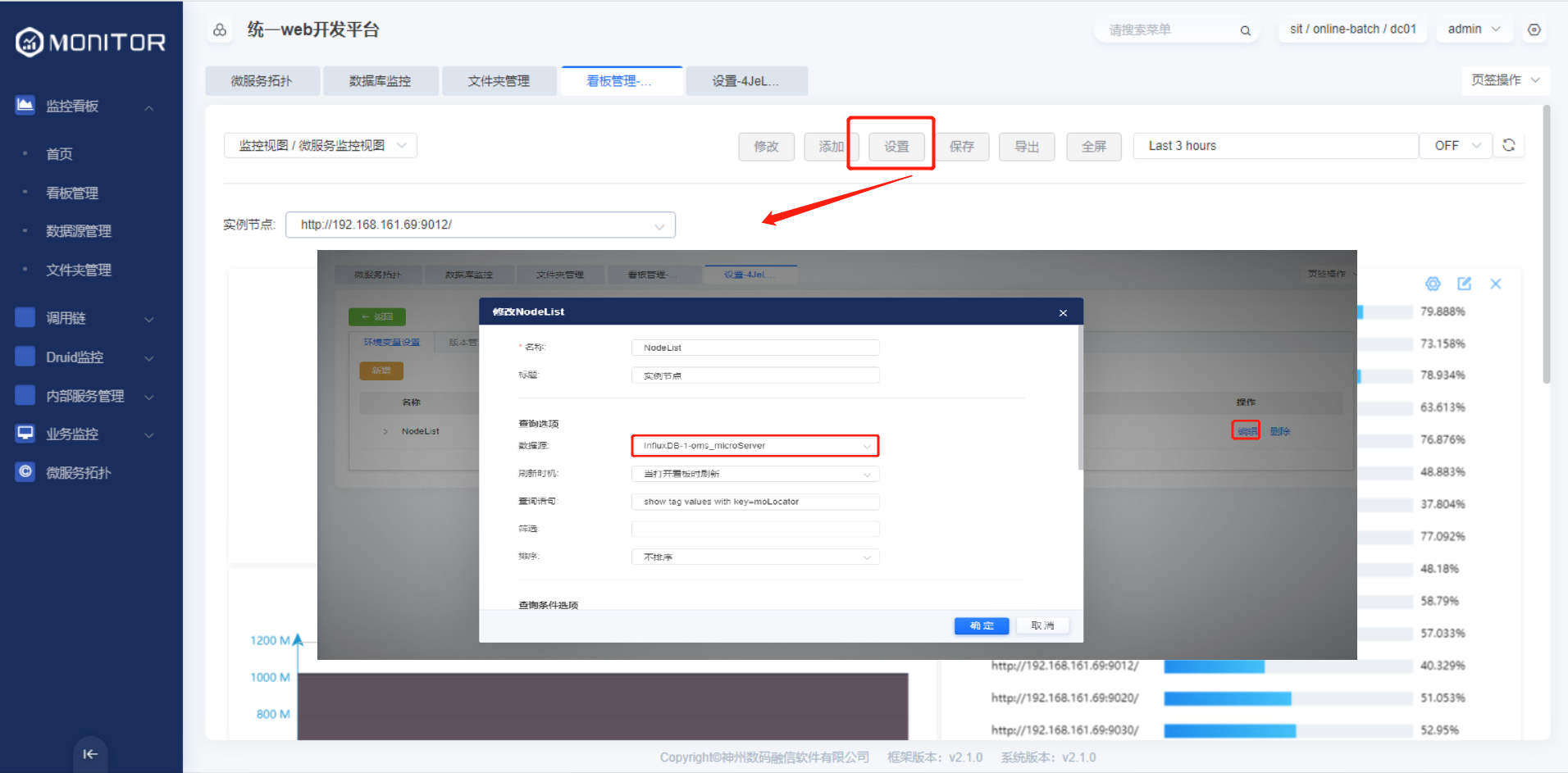
将随版本发布的看板json文件导入后,即可看到微服务的监控数据。
微服务监控数据:

微服务(带服务名)监控数据:
%E7%9B%91%E6%8E%A7%E6%95%B0%E6%8D%AE.png)
特别注意:
现场使用提供的JSON看板文件导入的后需要在相应的监控看板页面点击设置,修改真实数据源后保存。

也可以基于目前提供的数据源自定义监控看板的内容,其操作需要一定的influxdb、Prometheus、elasticsearch语法基础。
1.3.3.重要配置:
微服务监控数据:
应用端配置:
yaml
#spring actuactor监控配置
management:
endpoints:
web:
exposure:
#http方式包括需要公开的端点,如info,health等,"*"标识暴露所有端点。
include: "*"
base-path: /lhdmon
endpoint:
health:
#是否显示health的完整信息,缺省:never
show-details: always1.4.业务监控
1.4.1.日志中心
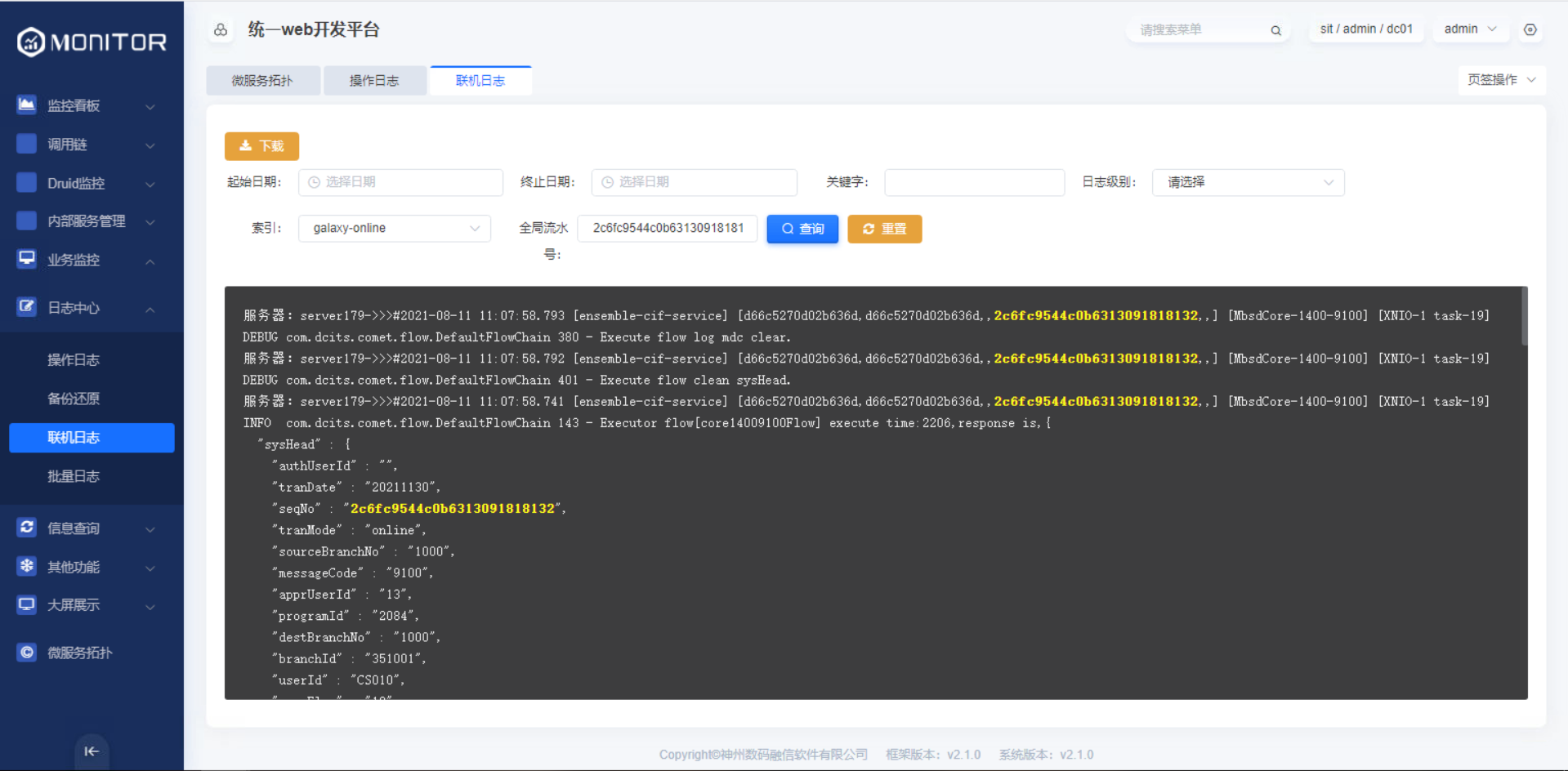
1.4.1.1.联机日志、批量日志
在各个应用生成日志文件后,由Filebeat负责采集日志并上送至Logstash,之后Logstash利用grok表达式对日志进行过滤,并根据转换成指定格式,上送至Elasticsearch中,最后由aries-log-center负责读取、备份日志。
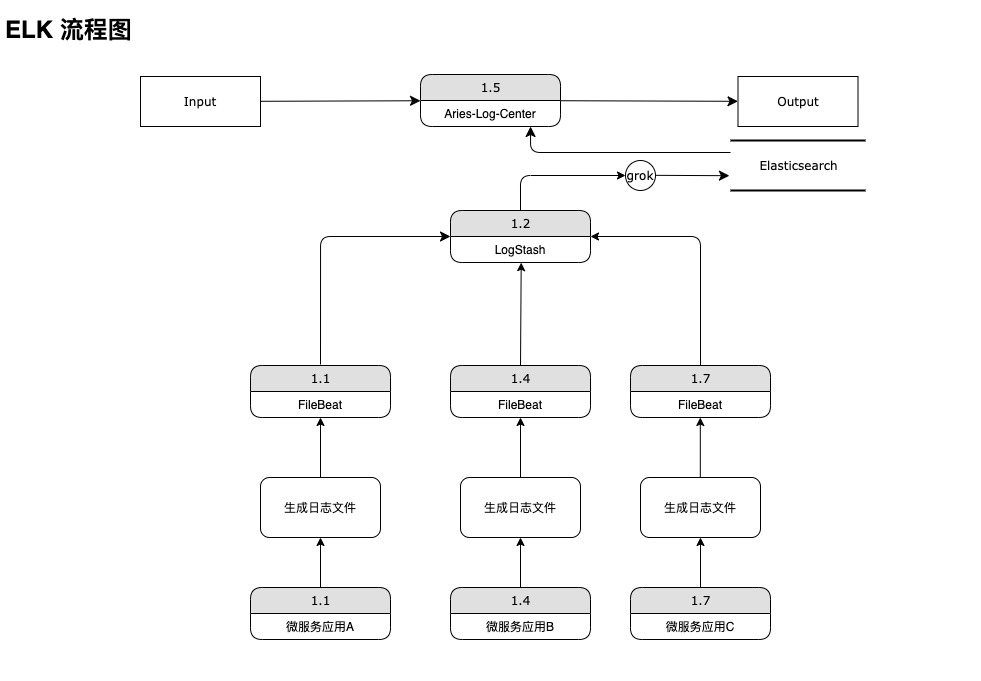
基于日志的起始时间、关键字、日志级别等可实现日志的查询。前端日志显示区滚动实现日志的分页查询。
1.4.1.2.重要配置
核心业务系统使用的ELK配置模板:
logback.xml的pattern配置:
xml
<property name="logging.pattern"
value="#%d{yyyy-MM-dd HH:mm:ss.SSS} [${spring.application.name}] [%ip:${port},%tid,%X{channelSeqNo},%X{jobRunId},%X{stepRunId}] [%X{serviceCode}-%X{messageType}-%X{m
essageCode}] [%thread] %-5level %logger{50} %line - %msg%n"/>filebeat采集端配置:
yaml
- type: log
enabled: true
fields:
service: galaxy-online
paths:
- /app/dcits/logs/ensemble-cif-service/*/*/*.log
multiline.pattern: ^\#
multiline.negate: true
multiline.match: after
- type: log
enabled: true
fields:
service: galaxy-online
paths:
- /app/dcits/logs/ensemble-cl-service/*/*/*.log
multiline.pattern: ^\#
multiline.negate: true
multiline.match: after
- type: log
enabled: true
fields:
service: galaxy-online
paths:
- /app/dcits/logs/ensemble-gl-service/*/*/*.log
multiline.pattern: ^\#
multiline.negate: true
multiline.match: after
- type: log
enabled: true
fields:
service: galaxy-online
paths:
- /app/dcits/logs/ensemble-ob-service/*/*/*.log
multiline.pattern: ^\#
multiline.negate: true
multiline.match: after
- type: log
enabled: true
fields:
service: galaxy-online
paths:
- /app/dcits/logs/ensemble-pf-service/*/*/*.log
multiline.pattern: ^\#
multiline.negate: true
multiline.match: after
- type: log
enabled: true
fields:
service: galaxy-online
paths:
- /app/dcits/logs/ensemble-rb-service/*/*/*.log
multiline.pattern: ^\#
multiline.negate: true
multiline.match: after
- type: log
enabled: true
fields:
service: galaxy-online
paths:
- /app/dcits/logs/ensemble-tae-service/*/*/*.log
multiline.pattern: ^\#
multiline.negate: true
multiline.match: afterlogstash的grok配置:
xml
grok {
match => { "message" => "\#%{TIMESTAMP_ISO8601:logdate}\s*\[%{DATA:springApplicationName}\]\s*\[%{IP:ip}\:%{NUMBER:port}\,TID:%{DATA:tId}\,(?
<channelSeqNo>[A-Za-z0
-9]*)\,(?
<jobRunId>[A-Za-z0-9]*)\,(?
<stepRunId>[A-Za-z0-9]*)\]\s*\[(?
<serviceCode>[A-z]*)\-(?
<messageType>[0-9]*)\-(?
<messageCode>[0-9]*)\]\s*\[(?
<threadId>[-A-z0-9 ]+)\]\s*%{LOGLEVEL:logLevel}\s*" }1.4.1.3.实例日志集成
在运维平台部署模块的应用列表中提供实例日志查询入口。
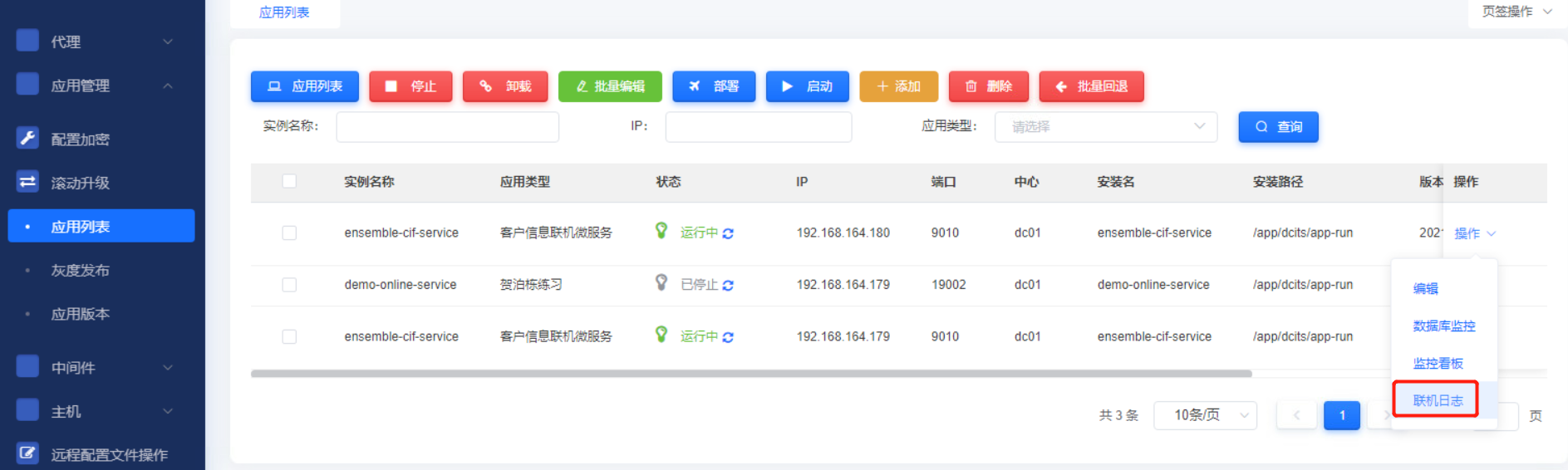
为了在部署列表中精准的查询到某个实例的日志,应用需要集成jupiter-log,该模块会获取应该所在的服务器ip并在日志打印ip信息,同时可在jupiter-log对日志的输出进行的扩展,可将jupiter-log中采集的字段信息进行打印,使后续的问题排查、链路分析更加简单、精准。
pom依赖
xml
<dependency>
<groupId>com.dcits.jupiter</groupId>
<artifactId>jupiter-log</artifactId>
</dependency>1.4.1.4.文件配置
在应用的 logback.xml中引入jupiter-logback.xml 并在日志输出时进行打印
jupiter-logback.xml示例:
xml
<?xml version="1.0" encoding="UTF-8"?>
<included>
<!-- ip使用自定义类去查 -->
<conversionRule conversionWord="ip" converterClass="com.dcits.jupiter.log.common.LogIpConfig"/>
<springProperty scope="context" name="port" source="server.port" defaultValue="8080"/>
<springProperty scope="context" name="serviceName" source="spring.application.name"/>
<springProperty scope="context" name="tenantId" source="galaxy.tenantId"/>
<springProperty scope="context" name="dataCenter" source="galaxy.dataCenter"/>
<springProperty scope="context" name="profile" source="galaxy.profile"/>
<springProperty scope="context" name="logicUnitId" source="galaxy.logicUnitId"/>
<springProperty scope="context" name="phyUnitId" source="galaxy.phyUnitId"/>
<springProperty scope="context" name="logback.dir" source="logging.file.path" defaultValue="./logs"/>
<springProperty scope="context" name="logback.maxHistory" source="logging.file.max-history" defaultValue="14"/>
<springProperty scope="context" name="logback.totalSizeCap" source="logging.file.total-size-cap"
defaultValue="30GB"/>
<springProperty scope="context" name="logback.maxFileSize" source="logging.file.max-size" defaultValue="10MB"/>
<property name="JUPITER_LOG_PATTERN"
value="#[%d{yyyy-MM-dd HH:mm:ss,SSS}] [%ip:${port}:${tenantId}:${profile}:${serviceName}:${logicUnitId}:${phyUnitId}:%X{J-TraceId:-}:%X{J-SpanId:-}:%X{J-SpanId-Pre:-}] [%thread] %-5level %logger{86}.%M:%L - %msg%n"/>
</included>logback.xml 重要配置示例:
xml
<configuration scan="true" scanPeriod="10 seconds" debug="false">
<contextName>logback</contextName>
<!-- 引入jupiter-log -->
<include resource="jupiter-logback.xml"/>
<springProperty scop="context" name="spring.application.name" source="spring.application.name"
defaultValue="ensemble"></springProperty>
<!--定义日志文件的存储地址 勿在 LogBack 的配置中使用相对路径-->
<property name="logging.path" value="../../logs"/>
<!--<property name="spring.application.name" value="ensemble-cif-service"/>-->
<property name="logging.maxHistory" value="30"/>
<property name="logging.maxFileSize" value="10MB"/>
<property name="logging.totalSizeCap" value="100GB"/>
<property name="logging.pattern"
value="#%d{yyyy-MM-dd HH:mm:ss.SSS} [${spring.application.name}] [%ip:${port},%X{X-B3-TraceId},%X{X-B3-SpanId},%X{X-B3-ParentSpanId},%X{channelSeqNo},%X{jobRunId},%X{stepRunId}] [%X{serviceCode}-%X{messageType}-%X{messageCode}] [%thread] %-5level %logger{50} %line - %msg%n"/>
<property name="logging.console"
</configuration>logstash的grok配置:
xml
grok {
match => { "message" => "\#%{TIMESTAMP_ISO8601:logdate}\s*\[%{DATA:springApplicationName}\]\s*\[%{IP:ip}\:%{NUMBER:port}\,TID:%{DATA:tId}\,(?
<channelSeqNo>[A-Za-z0
-9]*)\,(?
<jobRunId>[A-Za-z0-9]*)\,(?
<stepRunId>[A-Za-z0-9]*)\]\s*\[(?
<serviceCode>[A-z]*)\-(?
<messageType>[0-9]*)\-(?
<messageCode>[0-9]*)\]\s*\[(?
<threadId>[-A-z0-9 ]+)\]\s*%{LOGLEVEL:logLevel}\s*" }实例日志查询结果:
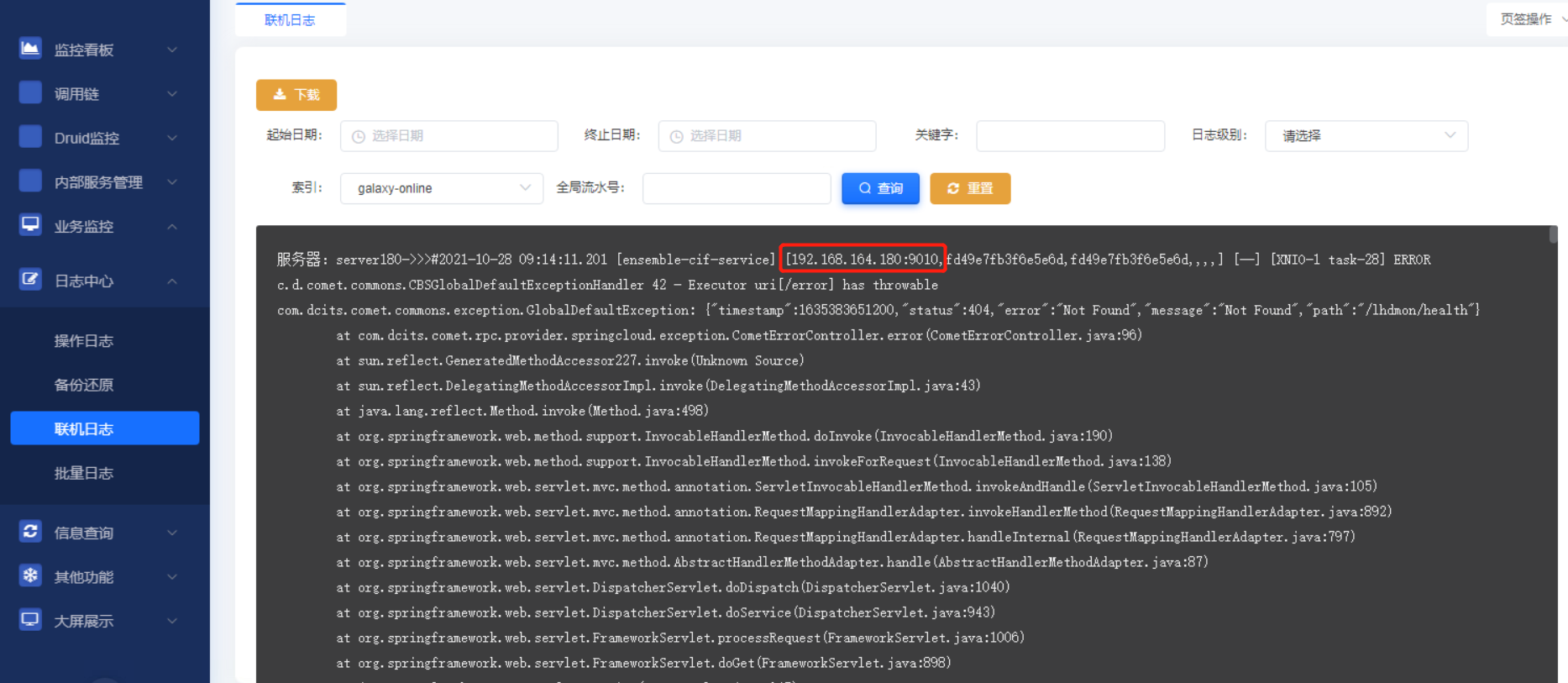
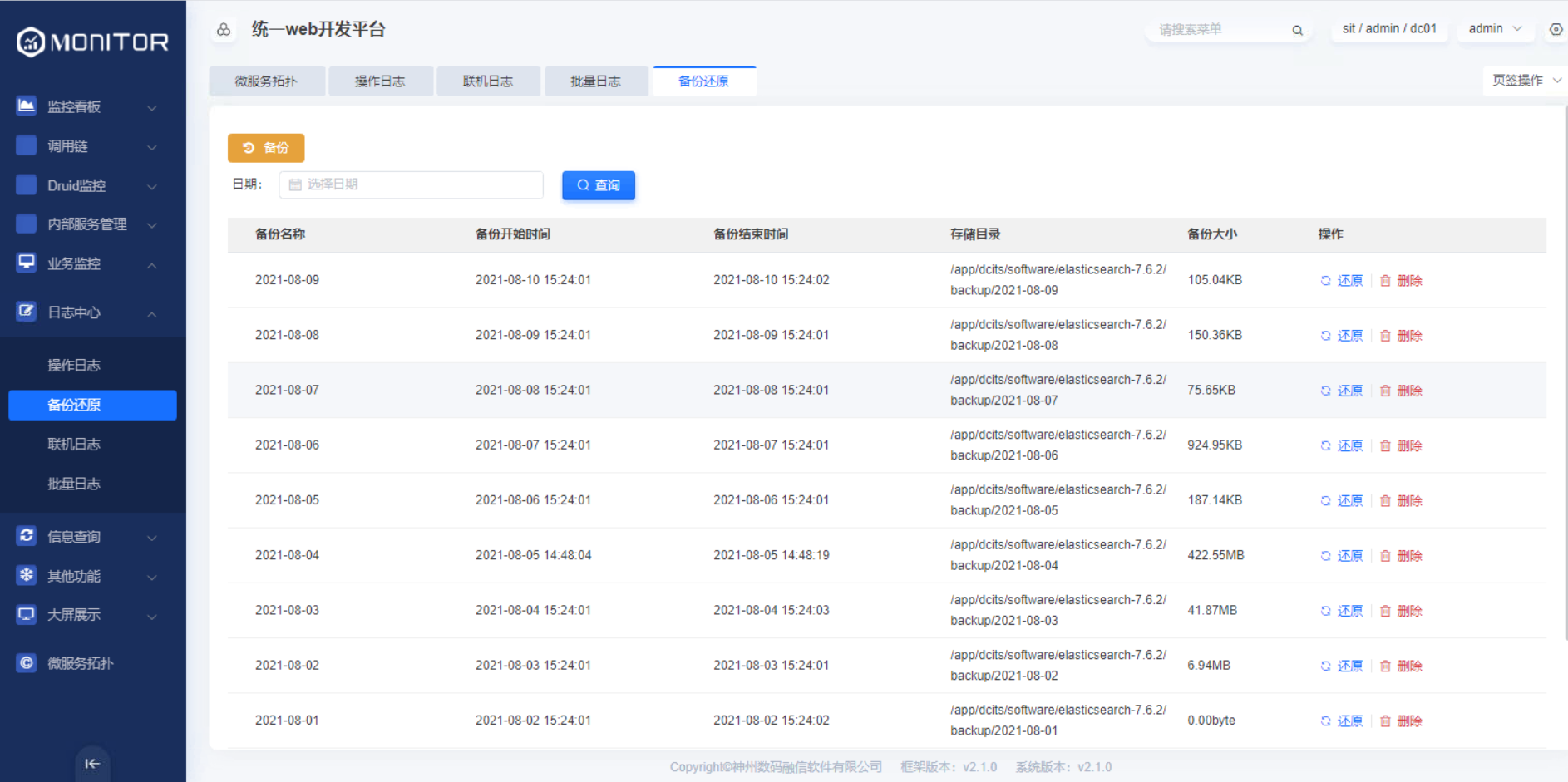
1.4.1.5.备份还原
日志文件是基于elasticsearch索引文件备份的,每天一个索引,可以选择某一天的索引文件进行备份。默认系统提供定时任务备份索引文件。
选择某个日期,对该日期的索引进行备份,备份后删除elasticsearch索引文件,同时可还原某个索引文件的备份。
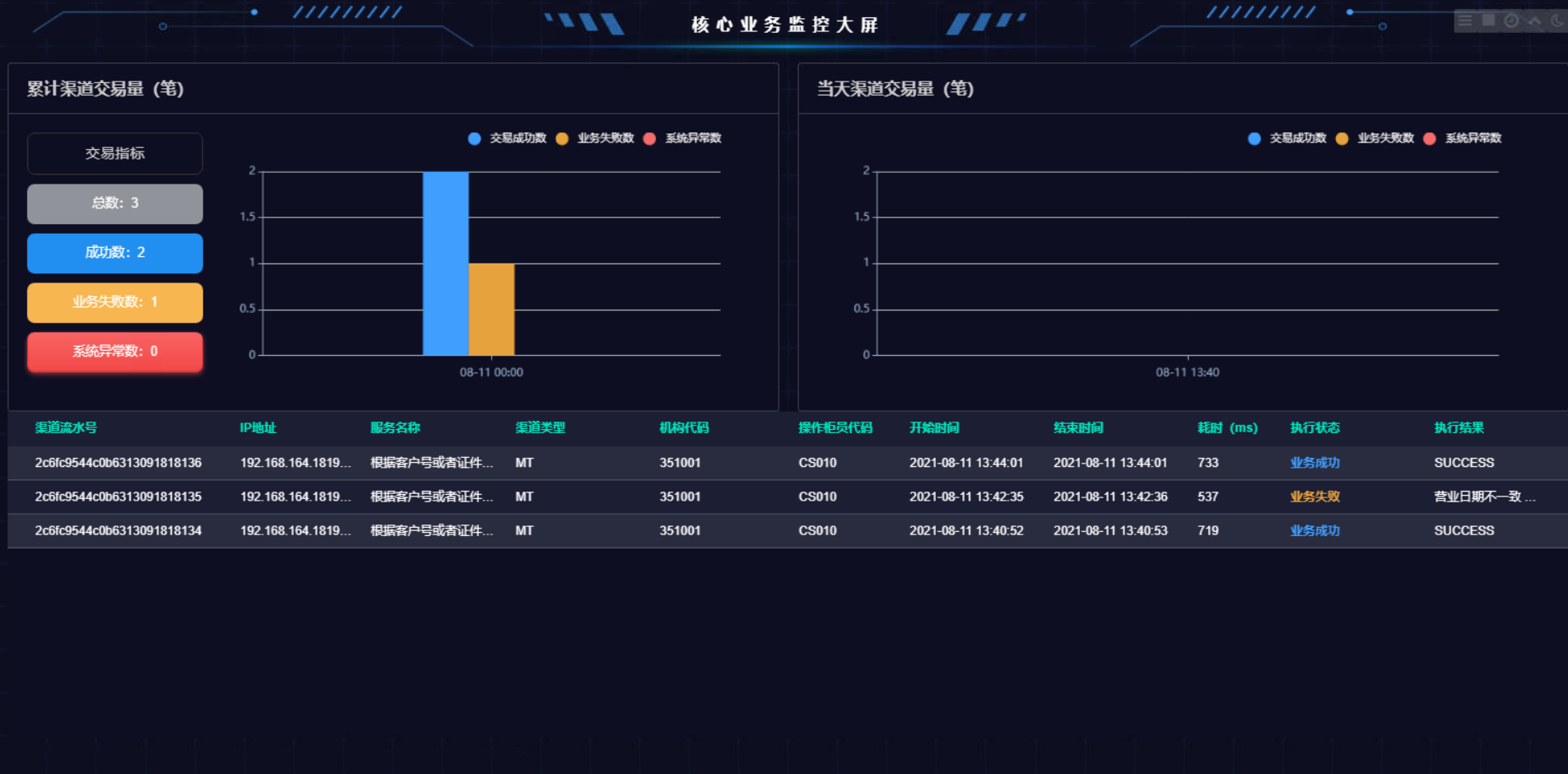
1.4.2.大屏展示
1.4.2.1.核心大屏
在influxdb中oms_monitor存储核心大屏监控的流水及统计数据。
该数据通过comet-gateway集成的aries-collect-transaction流水采集的sdk包,将采集到数据推送到kafka。monirot-business模块消费kafka上的数据存储到influxdb的oms_monitor数据库中。
流水数据influxdb的存储rp策略是1h,即1h前的数据会自动删除。
1.4.2.2.重要配置
comet-gateway网关配置:
properties
#核心大屏开关
monitor.switchOn=true
##用于建立与kafka集群连接的host:port组。数据将会在所有servers上均衡加载。多个host:port之间用逗号隔开
kafka.producer.bootstrapServer=10.7.20.44:9092
#procuder需要多少个broker返回的确认信号
#acks=0 设置为0表示producer不需要等待任何确认收到的信息
#acks=1设置为1意味着至少要等待leader已经成功将数据写入本地log,但是并没有等待所有follower是否成功写入
#acks=all设置为all意味着leader需要等待所有备份都成功写入日志
kafka.producer.acks=0
#该配置默认为0,如果设置的值大于0,客户端将重新发送之前发送失败的数据
kafka.producer.retries=0
##topic
topicName=tranTopic
##批量的大小
kafka.producer.batchSize=16384
## 时间延时
kafka.producer.lingerMs=0
#生产者可用于缓冲等待发送到服务器的记录的总字节数
kafka.producer.bufferMemory=33554432
#Consumer等待请求响应的最大时间量
kafka.producer.requestTimeoutMs=45000
#关键字的序列化类
kafka.producer.keySerializer=org.apache.kafka.common.serialization.StringSerializer
#值的序列化类
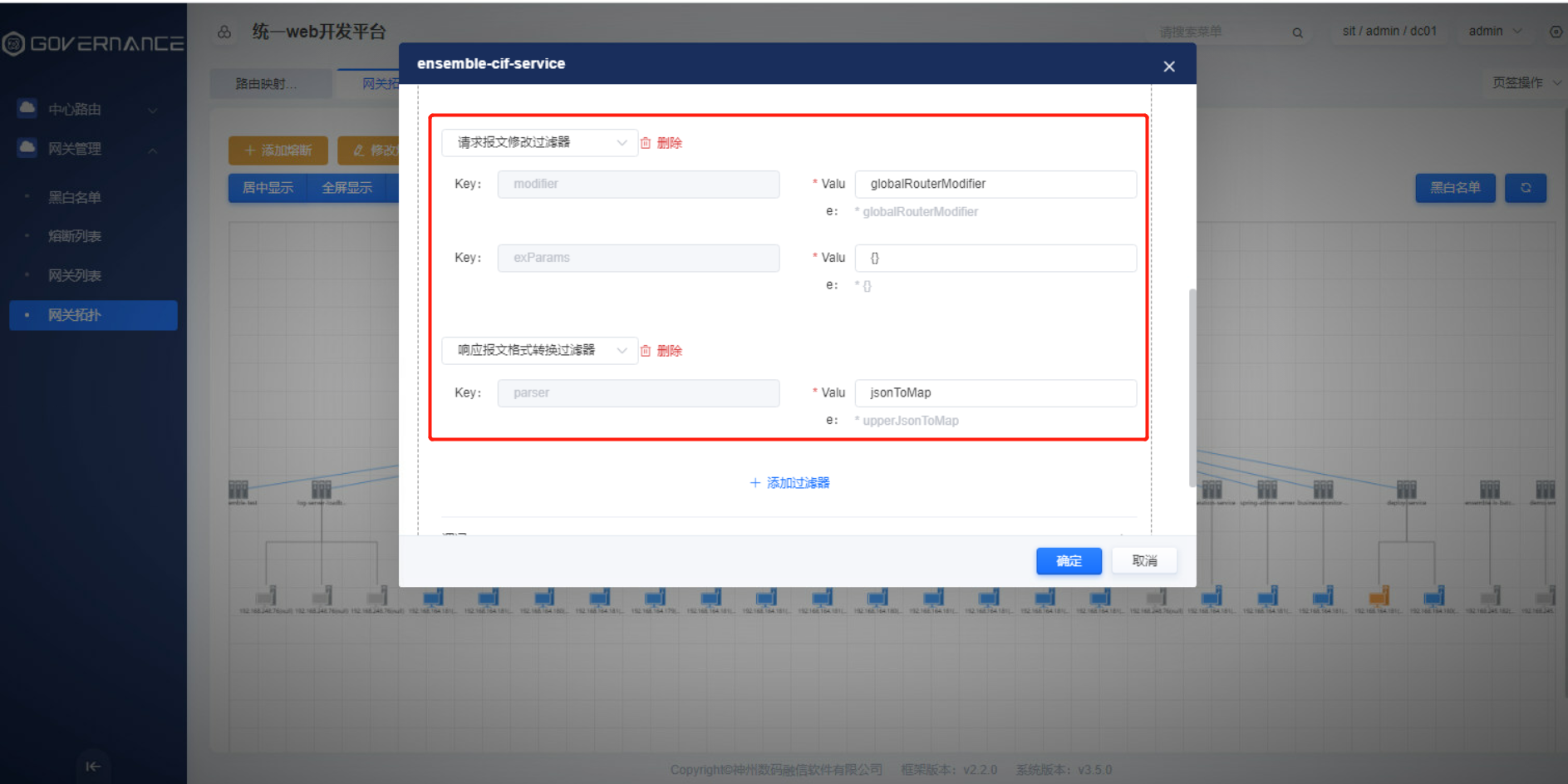
kafka.producer.valueSerializer=org.apache.kafka.common.serialization.StringSerializer在网关拓扑中配置各微服务模块请求报文修改过滤器和相应报文格式修改过滤器:
核心大屏监控数据需要网关在该模块上配置请求报文修改过滤器和相应报文修改过滤器,否则大屏监控数据不能监控到。
aries-monitor业务监控模块kafka地址配置:
yaml
kafka:
timer:
delay: 500 #单位:ms
interval: 5000 #单位:ms
topic: tranTopic
bootstrapServer: oms.mq-kafka-server:9092
groupId: tranGroup
enableAutoCommit: true
autoCommitIntervalMs: 1000
autoOffsetReset: latest
sessionTimeoutMs: 30000
maxPollRecords: 300
keyDeserializer: org.apache.kafka.common.serialization.StringDeserializer
valueDeserializer: org.apache.kafka.common.serialization.StringDeserializer1.4.3.信息查询
1.4.3.1.统一流水
监控中心提供统一流水查询页签,通过网关过滤器拦截流水记录报文字段信息存入kafka后,monitor-business消费kafka数据到GW_TRAN_INFO分表中,GW_TRAN_INFO表按照交易日期进行分表,即每天的流水数据入当天的分表,总计有8张分表( 0-7),GW_TRAN_CLEAN_RECORD表会根据交易日期确定当前流水存入哪个分表,定时任务清理哪个分表。

1.4.3.2.统一流水查询视图
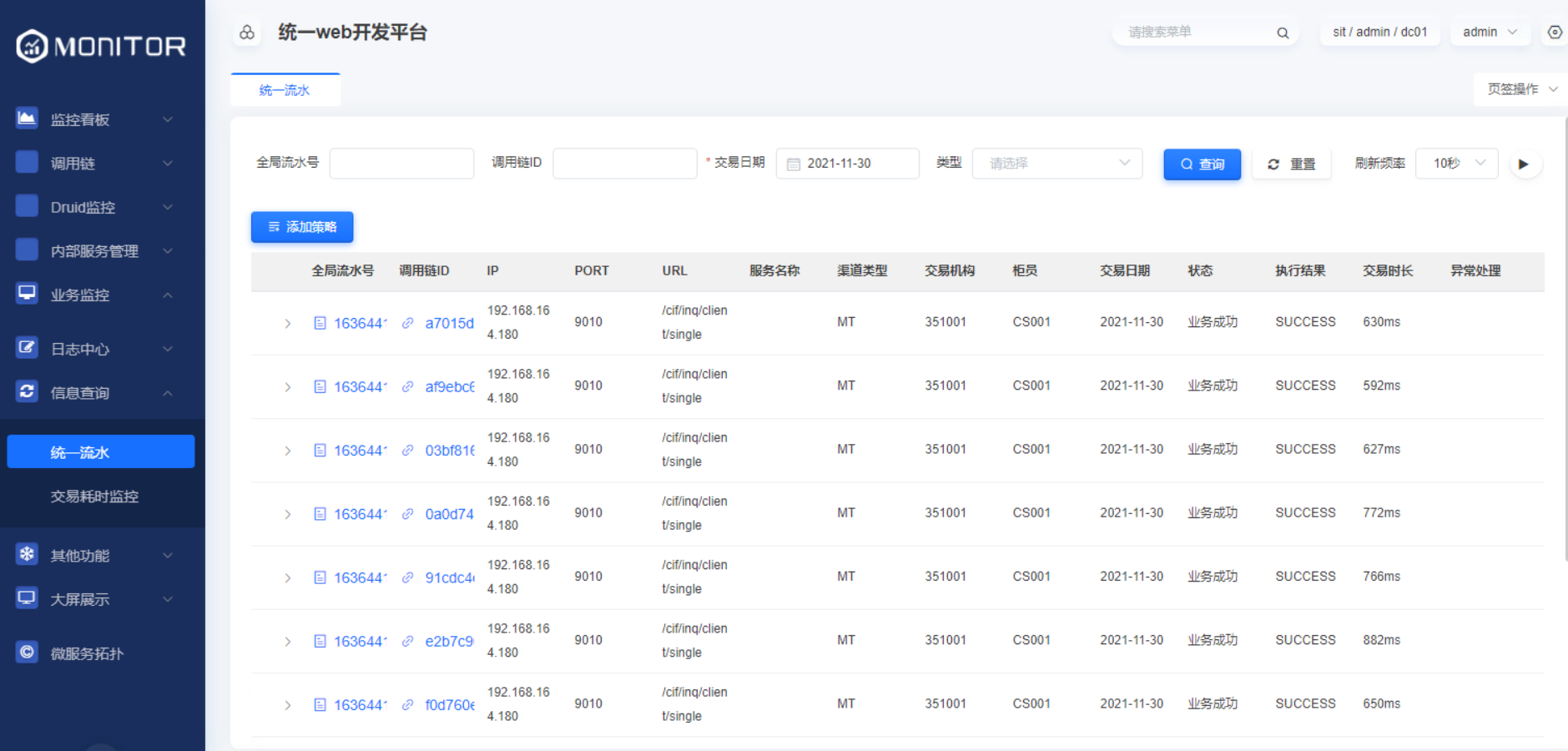
1.4.3.3.统一流水登记策略
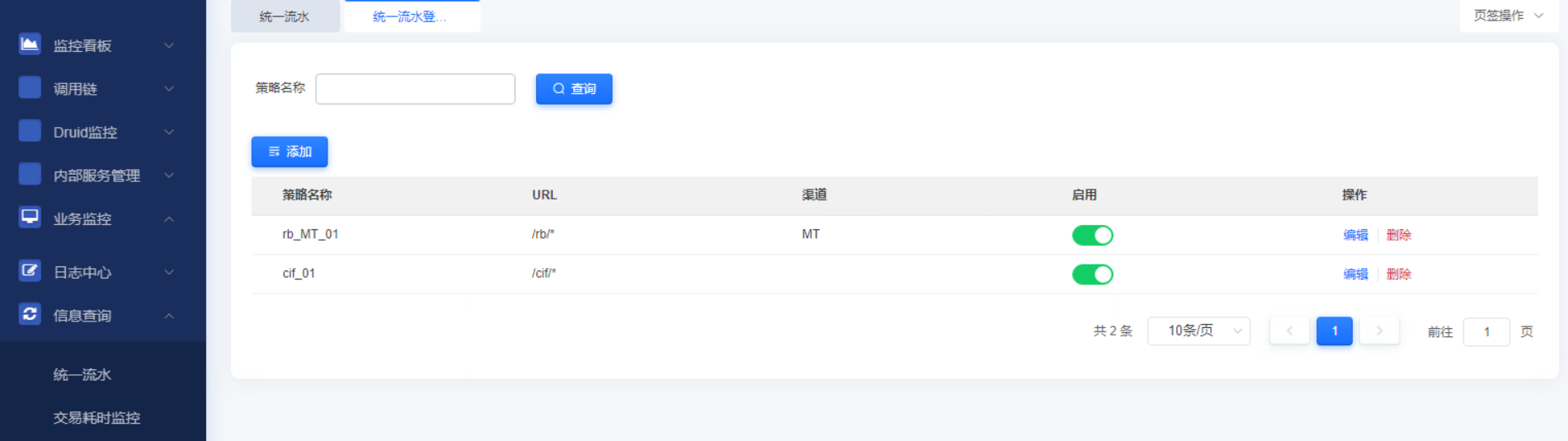
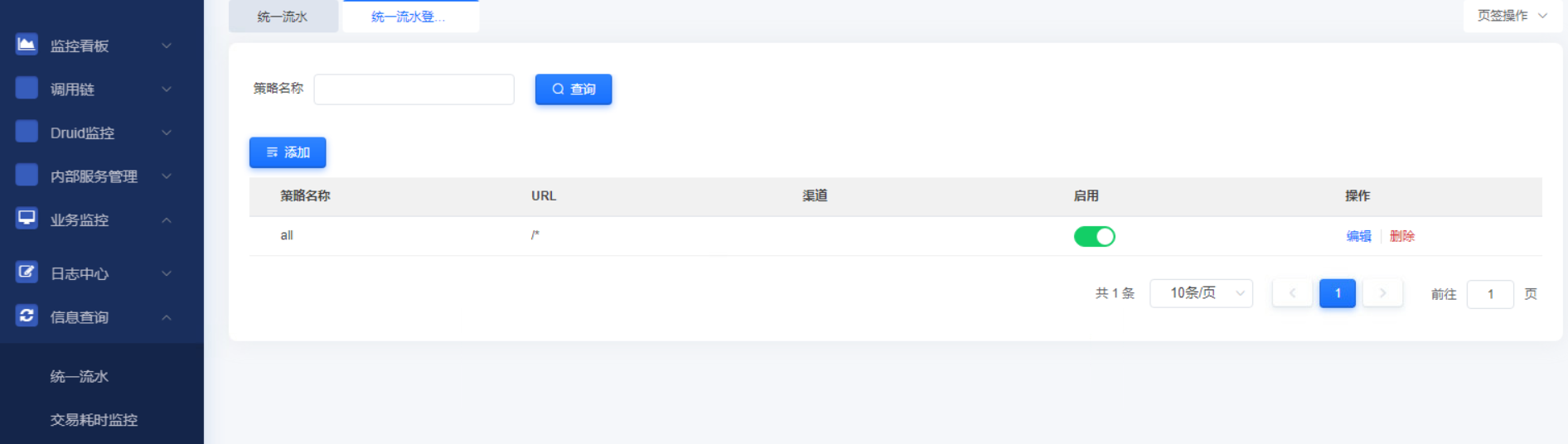
可设置统一流水登记策略。如需登记所有流水则请求url配置/*即可。默认只登记系统失败和业务失败信息。修改后无需重启实时生效。
登记请求url为/rb开头且渠道类型为MT和请求url为/cif开头的策略配置如下:
登记所有流水配置如下:
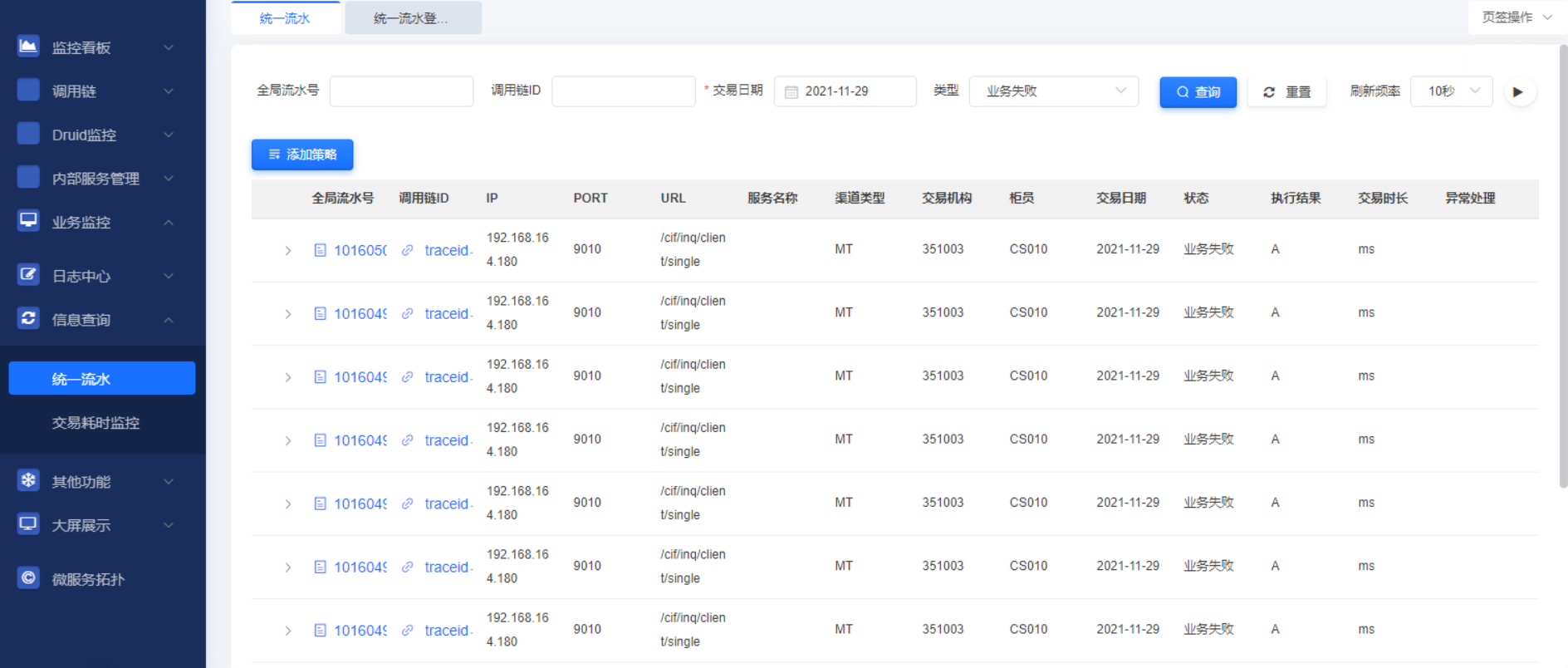
1.4.3.4.业务失败查询
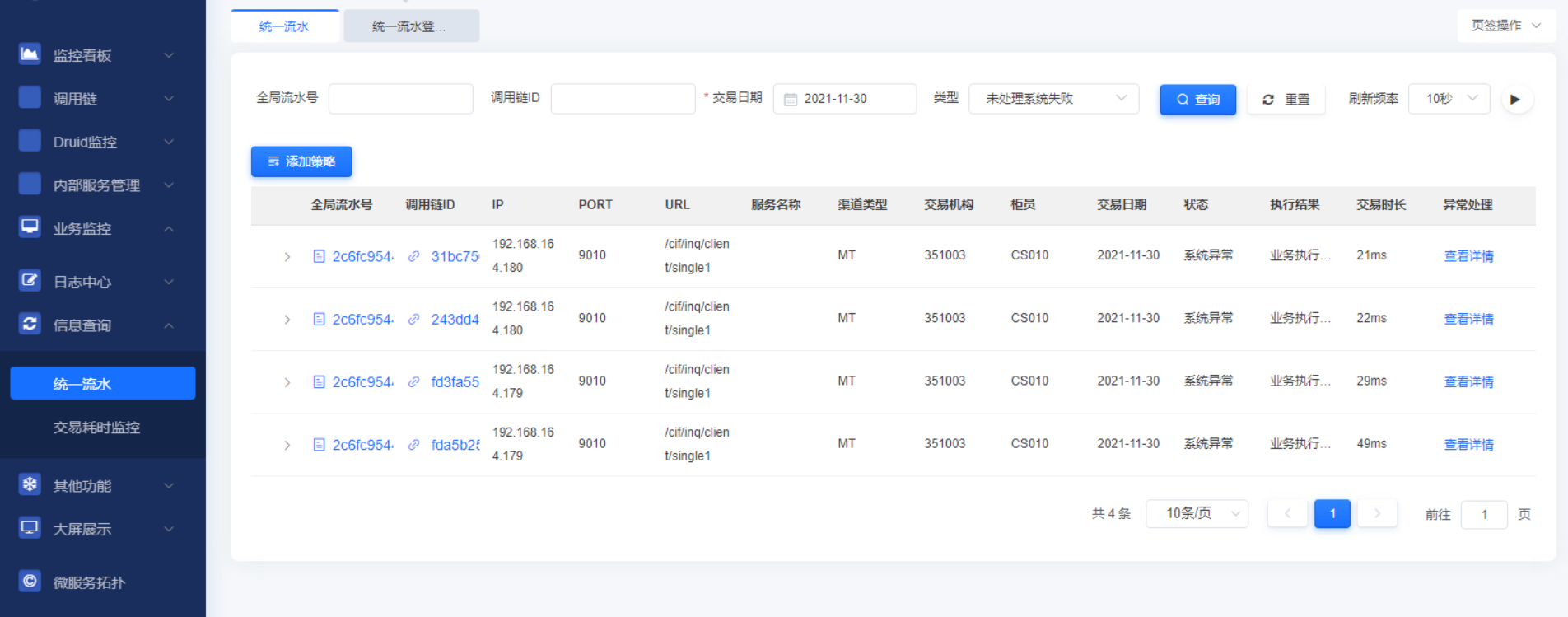
1.4.3.5.未处理系统失败查询
1.4.3.6.已处理系统失败查询
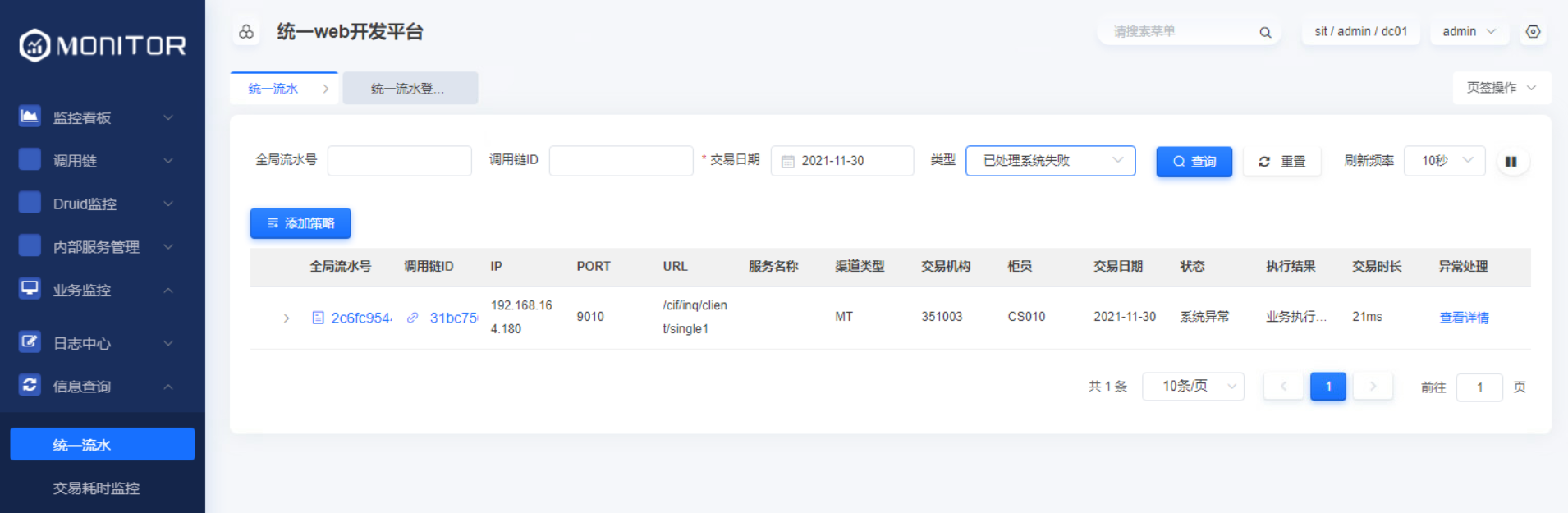
1.4.3.7.数据清理
数据清理定时任务配置:
yaml
aries:
schedule:
clean:
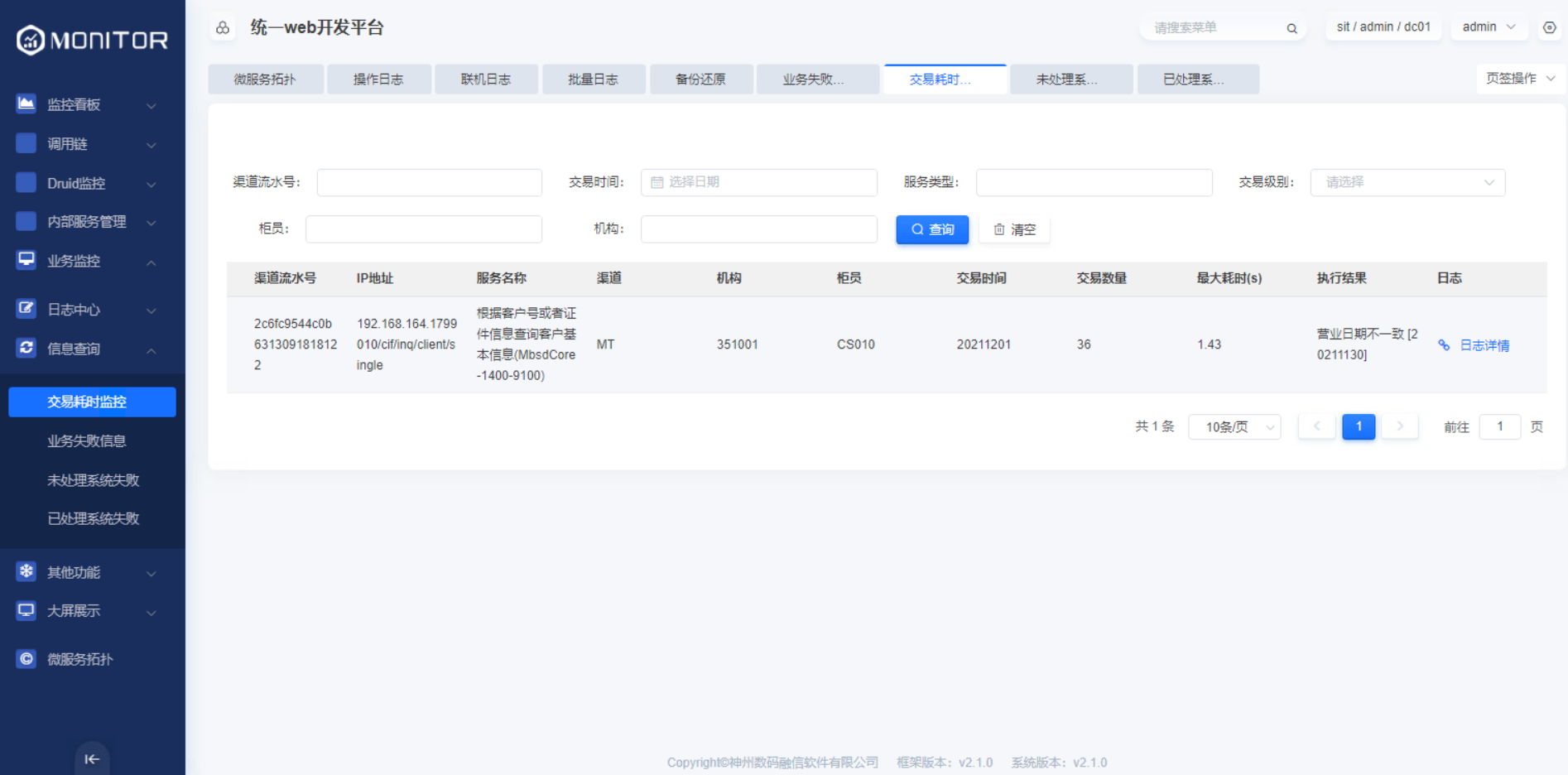
trans: 0 0 18-20 1/1 * ? #清理定时任务,默认:从每天 18 - 20 之间,每小时执行一次1.4.3.8.交易耗时监控
通过在yml里面配置aries.businessmonitor.bigscreen.business.overtime=1000参数的值,会将交易耗时大于该参数值的交易记录到OMS_OVERTIMETRANS_INFO表中。
1.4.4.其他功能
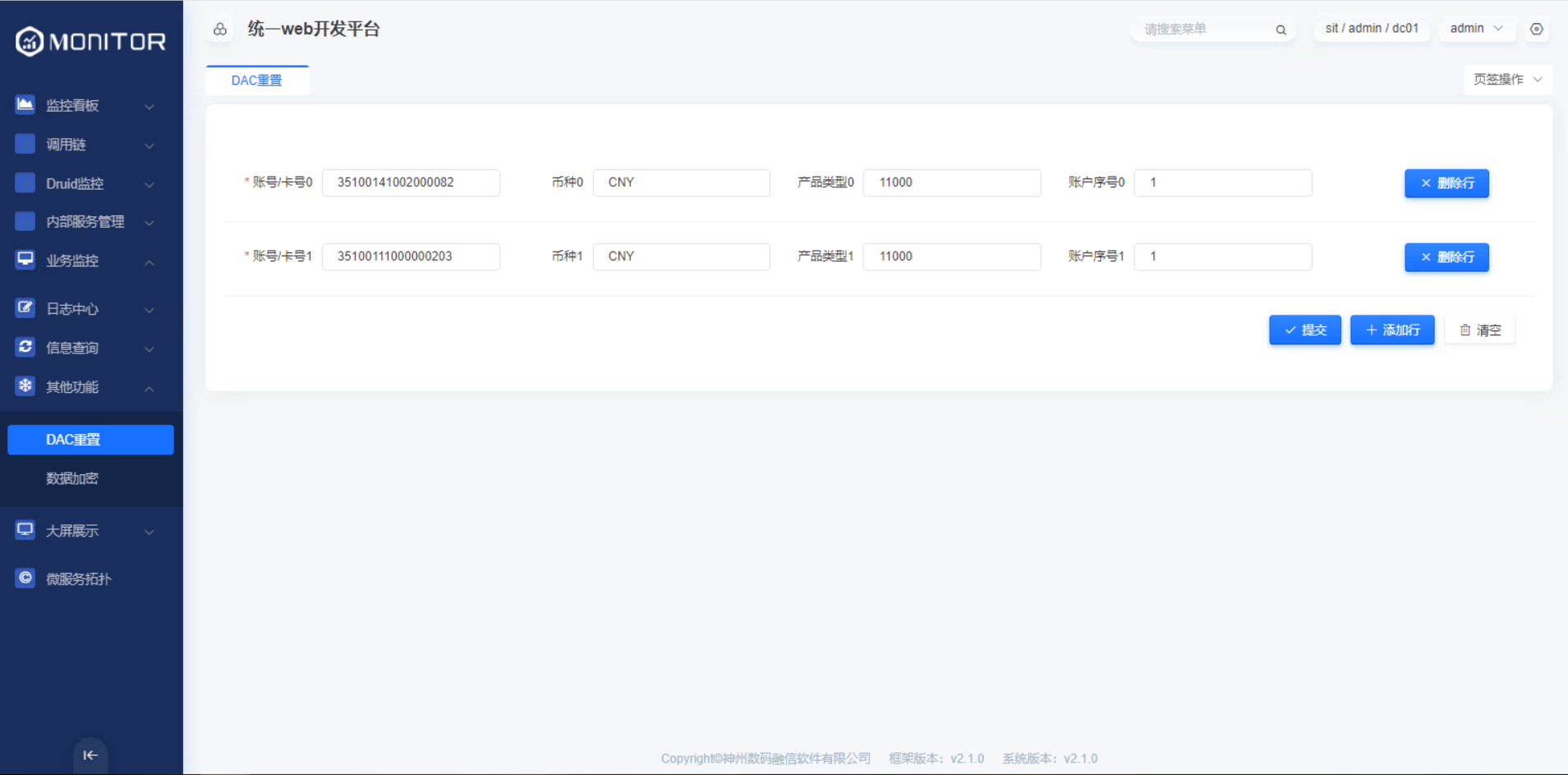
1.4.4.1.DAC重置
在monitor-business模块的yml配置文件中配置dac重置的接口aries.businessmonitor.galaxy.dac.server=http://192.168.161.128:8081/rb/nfin/dac/reset
DAC重置成功后会在操作日志中记录相关操作日志。
1.5.Prometheus监控
1.5.1.主机监控
1.5.1.1.prometheus配置:
在每个需要监控的服务器上安装node_exporter服务,启动后,将exporter暴露的ip: port/metrics参考下图配置到prometheus.yml配置文件中。多个节点需要配置多个job。
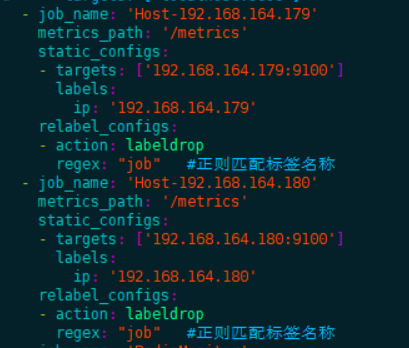
yaml
- job_name: 'Host-192.168.164.179'
metrics_path: '/metrics'
static_configs:
- targets: [ '192.168.164.179:9100' ]
labels:
ip: '192.168.164.179'
- job_name: 'Host-192.168.164.180'
metrics_path: '/metrics'
static_configs:
- targets: [ '192.168.164.180:9100' ]
labels:
ip: '192.168.164.180'1.5.1.2.主机监控看板:
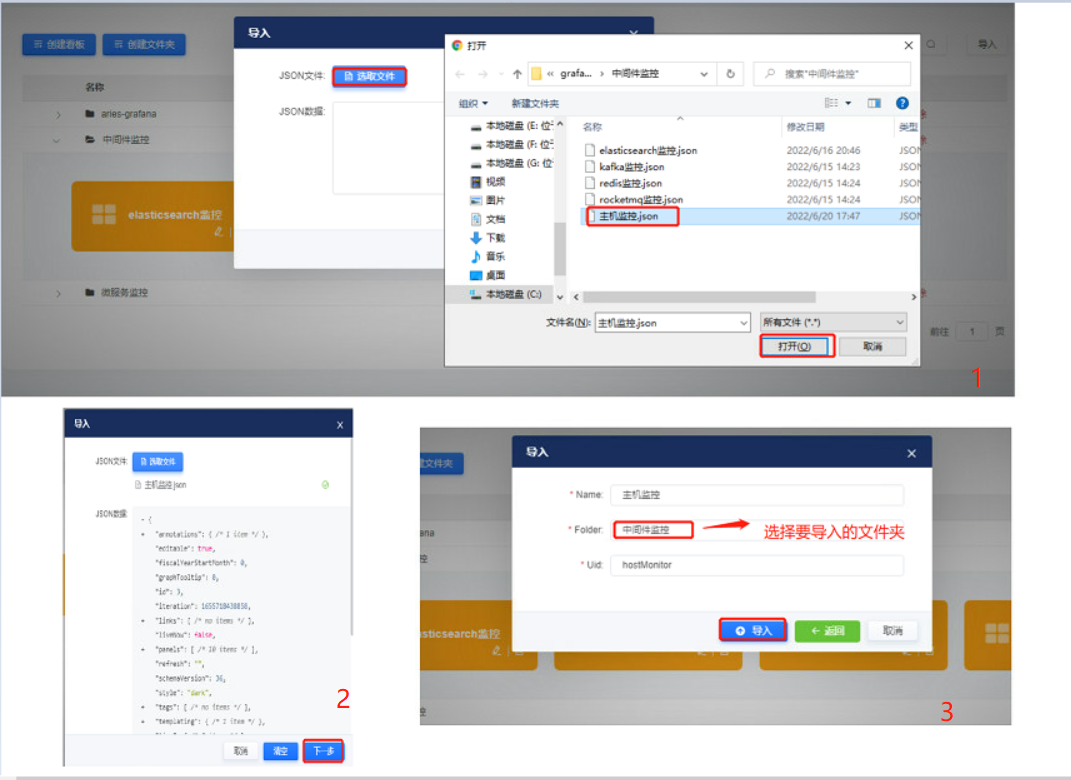
将prometheus/host-monitor.json看板文件参考下面步骤导入看板。
创建prometheus数据源
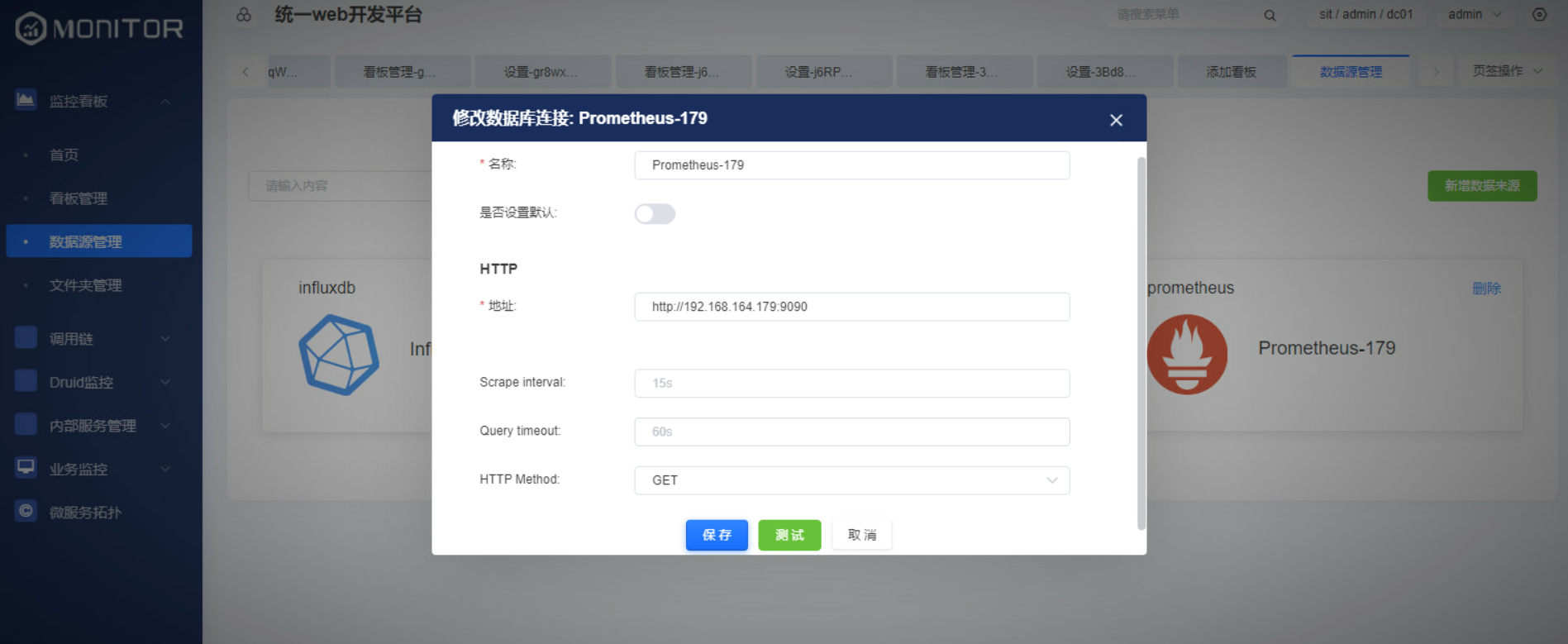
导入看板文件
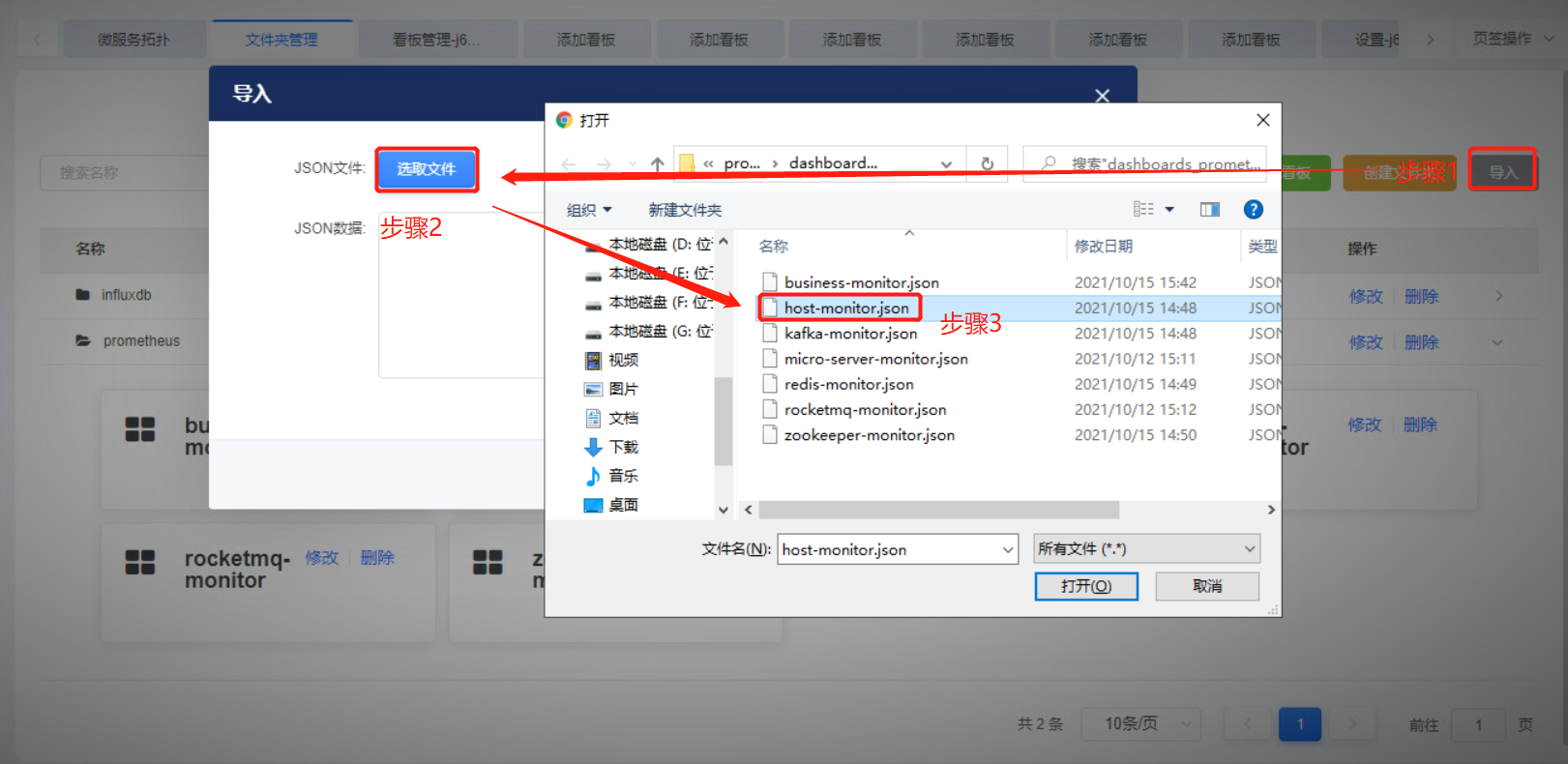
选择需要导入到的文件夹,并将指标项中的数据源修改为真实数据源。
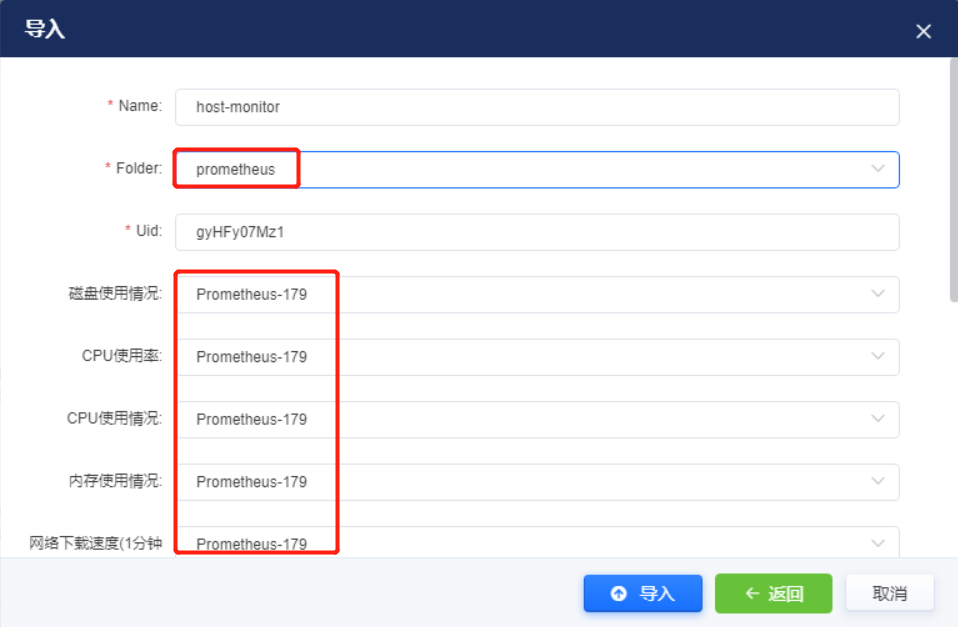
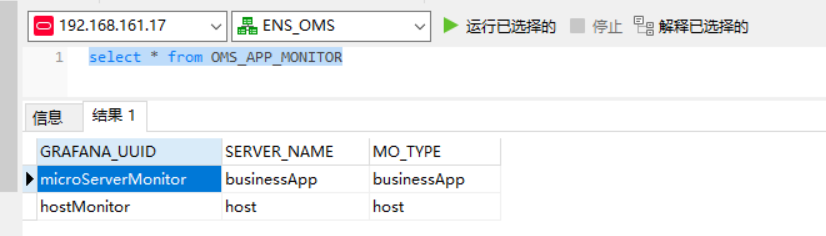
主机监控的Uid必须为hostMonitor,业务应用的jvm监控的Uid必须为microServerMonitor,否则无法从主机列表和应用列表页面跳转到监控页面,如需修改则修改deploy模块数据库中OMS_APP_MONITOR 表的grafana看板id。该表中目前配置主机监控看板id和微服务监控看板id,分别对应主机页面跳转监控看板和应用列表跳转监控看板。其他看板id可随意更改,不重复即可。
设置grafana看板环境变量所使用的数据源
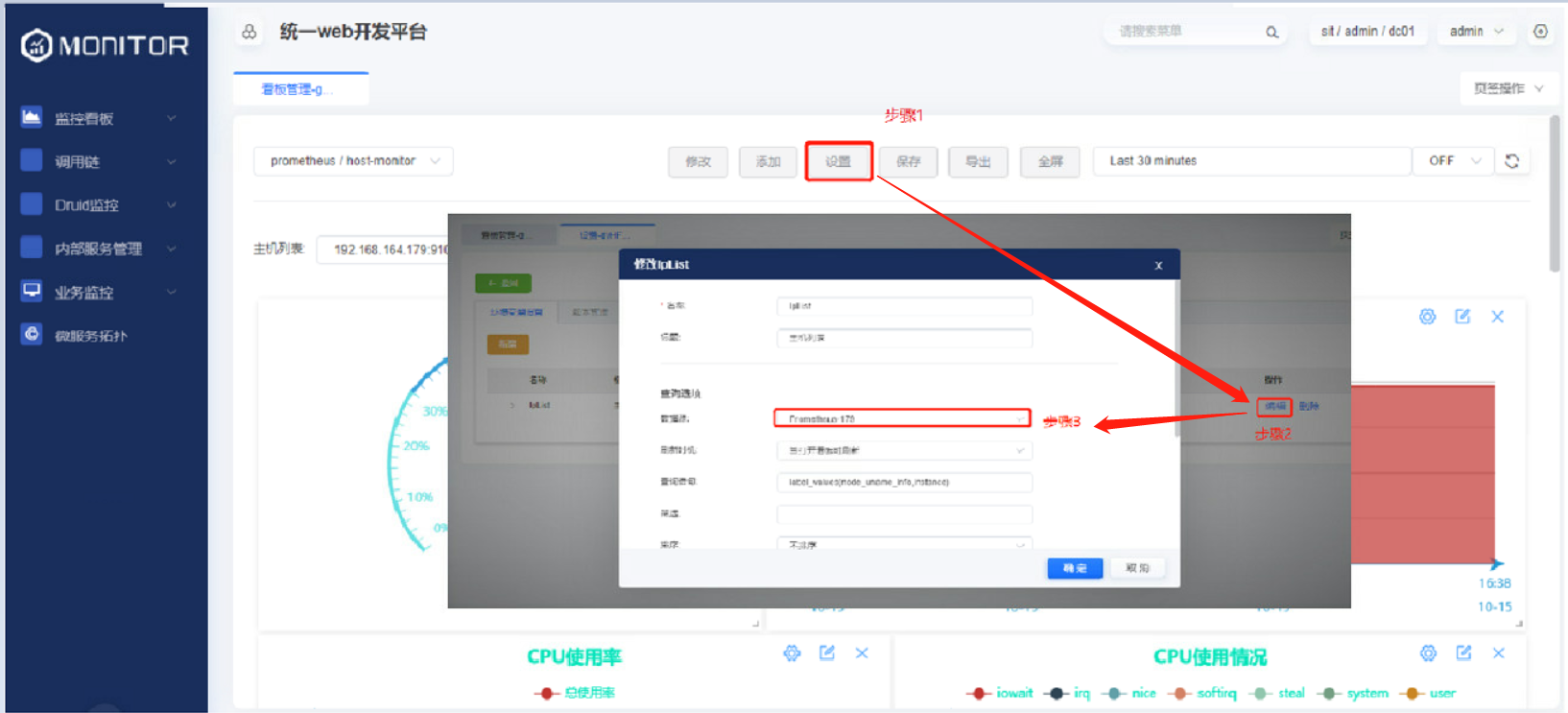
由于导出的json看板文件中携带部分环境相关的IP地址,故需要按照下图的步骤重新保存下看板。
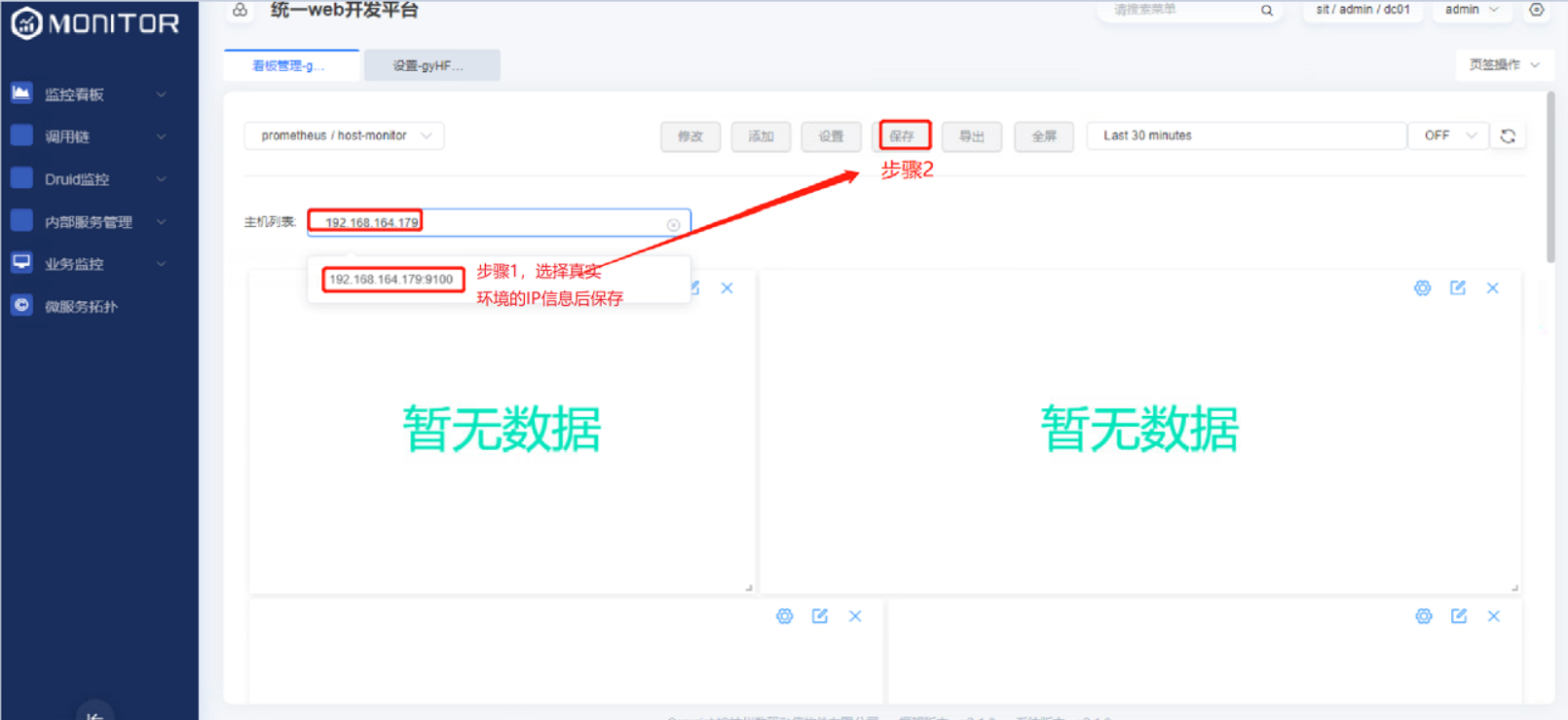
1.5.1.3.监控视图
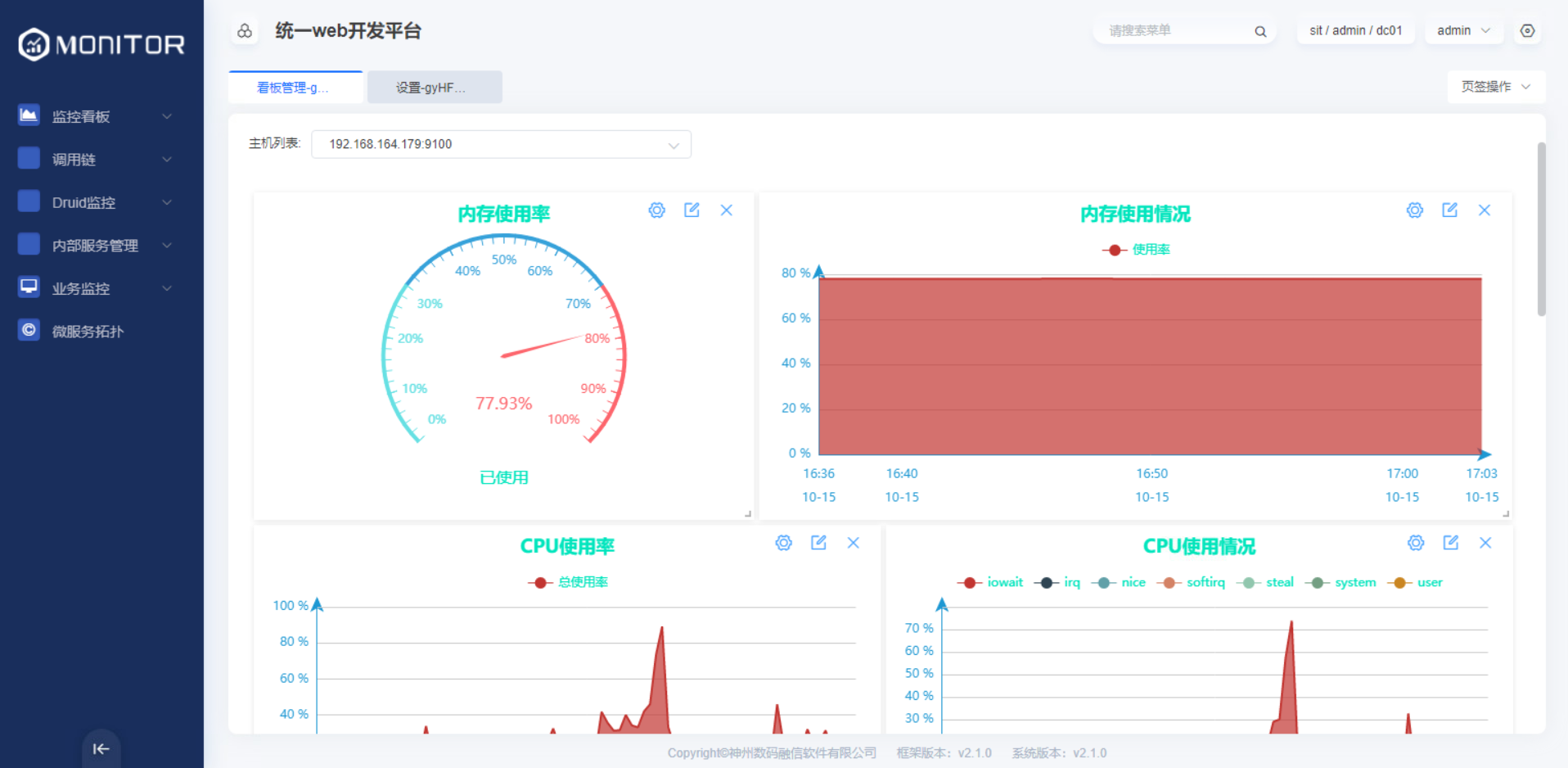
保存完成后即可看到主机的监控信息:
1.5.2.开源中间件监控
1.5.2.1.redis中间件监控
prometheus配置:
在redis所在服务器上安装redis_exporter服务,启动后,将exporter暴露的ip:port/metrics参考下图配置到prometheus.yml配置文件中。多个节点使用逗号分隔。

yaml
- job_name: 'RedisMonitor-180'
metrics_path: '/metrics'
static_configs:
- targets: [ '192.168.164.180:9121' ]
labels:
ip: '192.168.164.180:6379'redis监控看板:
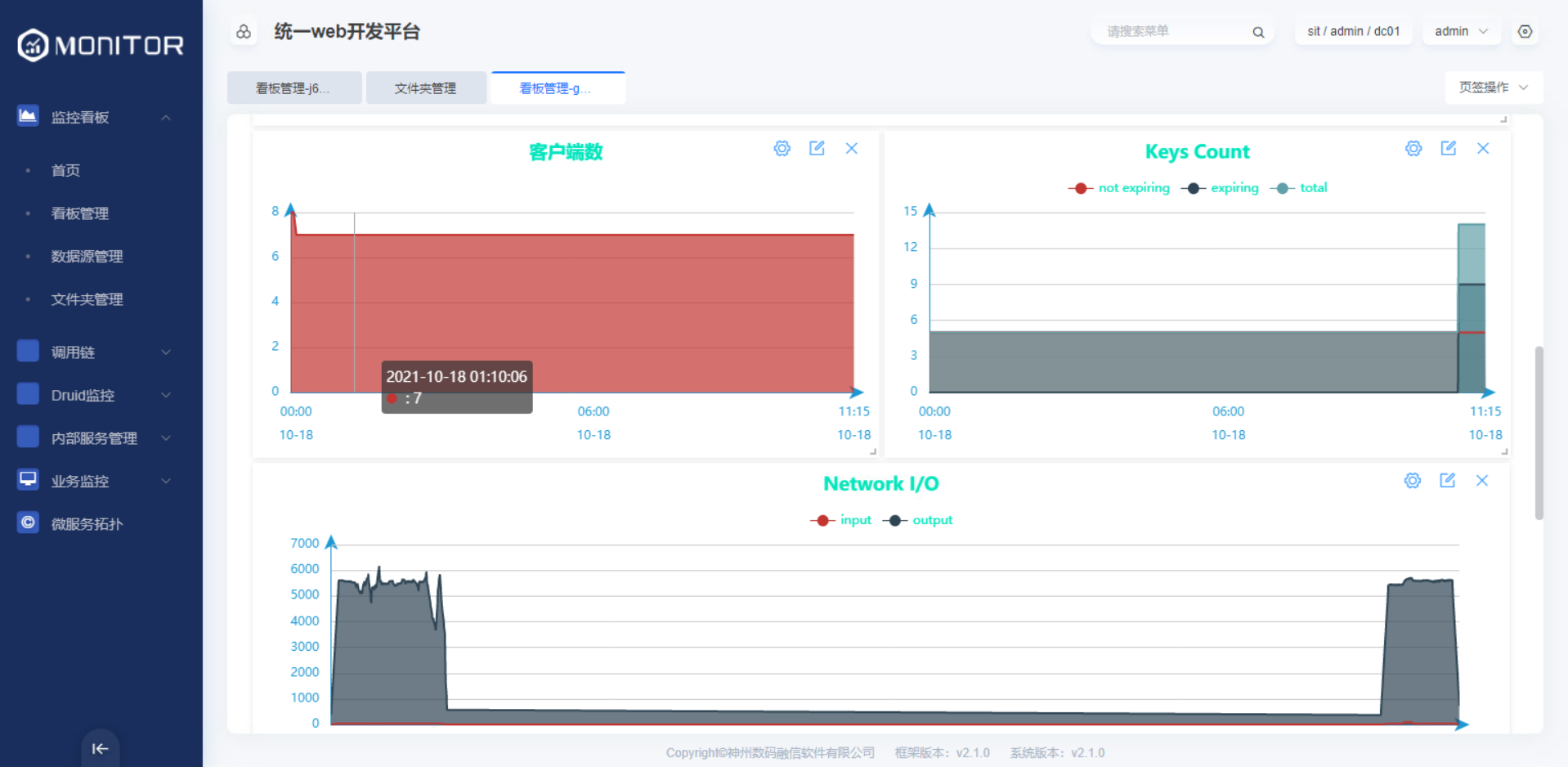
将prometheus/redis-monitor.json看板文件参考主机监控看板步骤导入。
监控视图
1.5.2.2.zookeeper中间件监控
prometheus配置:
在zookeeper所在服务器上安装zookeeper_exporter服务,启动后,将exporter暴露的ip: port/metrics参考下图配置到prometheus.yml配置文件中。多个节点使用逗号分隔。
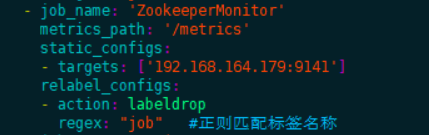
yaml
- job_name: 'ZookeeperMonitor'
metrics_path: '/metrics'
static_configs:
- targets: [ '192.168.164.179:9141' ]
labels:
ip: '192.168.164.179:2181'zookeeper监控看板:
将prometheus/zookeeper-monitor.json看板文件参考主机监控看板步骤导入。
监控视图
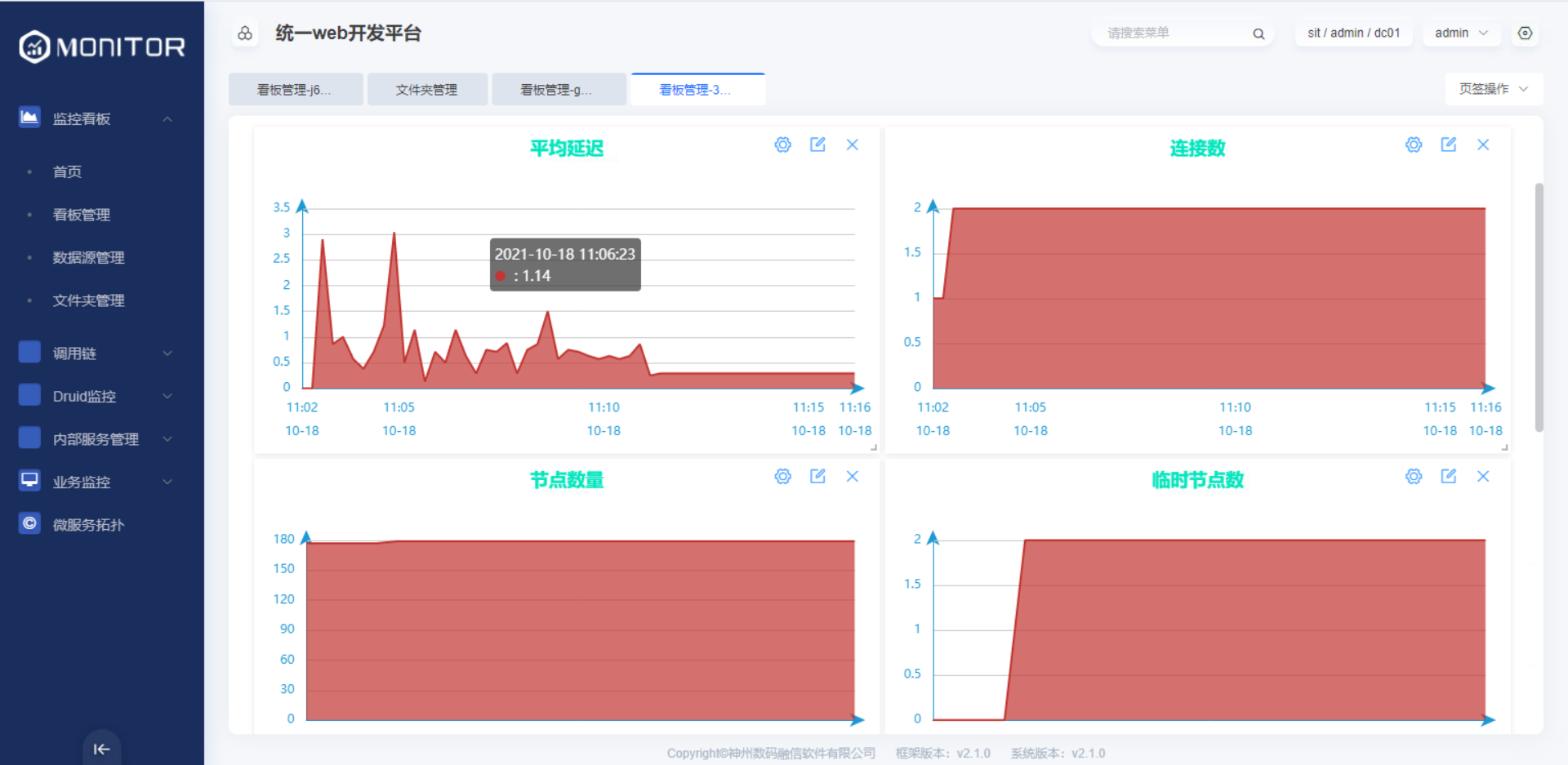
1.5.2.3.kafka中间件监控
prometheus配置:
在kafka所在服务器上安装kafka_exporter服务,启动后,将exporter暴露的ip:port/metrics参考下图配置到prometheus.yml配置文件中。多个节点使用逗号分隔。

yaml
- job_name: 'KafkaMonitor'
metrics_path: '/metrics'
static_configs:
- targets: [ '192.168.164.179:9308' ]
labels:
ip: '192.168.164.179:9092'kafka监控看板:
将prometheus/kafka-monitor.json看板文件参考主机监控看板步骤导入。
监控视图
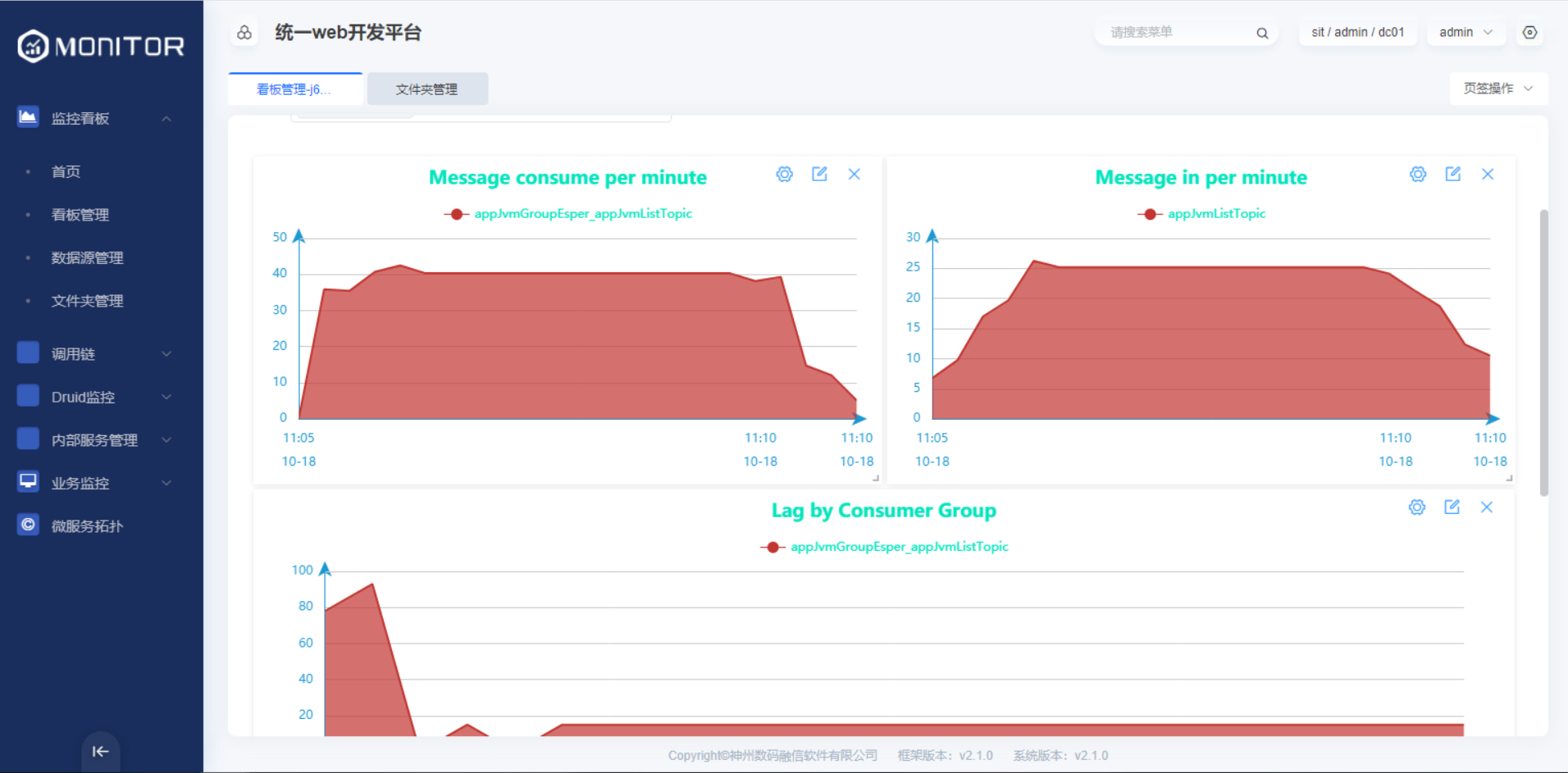
1.5.2.4.rocketmq中间件监控
prometheus配置:
在rocketmq所在服务器上安装rocketmq_exporter服务,启动后,将exporter暴露的ip: port/metrics参考下图配置到prometheus.yml配置文件中。多个节点使用逗号分隔。
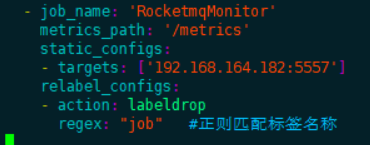
yaml
- job_name: 'RocketmqMonitor'
metrics_path: '/metrics'
static_configs:
- targets: [ '192.168.164.182:5557' ]
labels:
ip: '192.168.164.182:9876'rocketmq监控看板:
将prometheus/rocketmq-monitor.json看板文件参考主机监控看板步骤导入。
监控视图
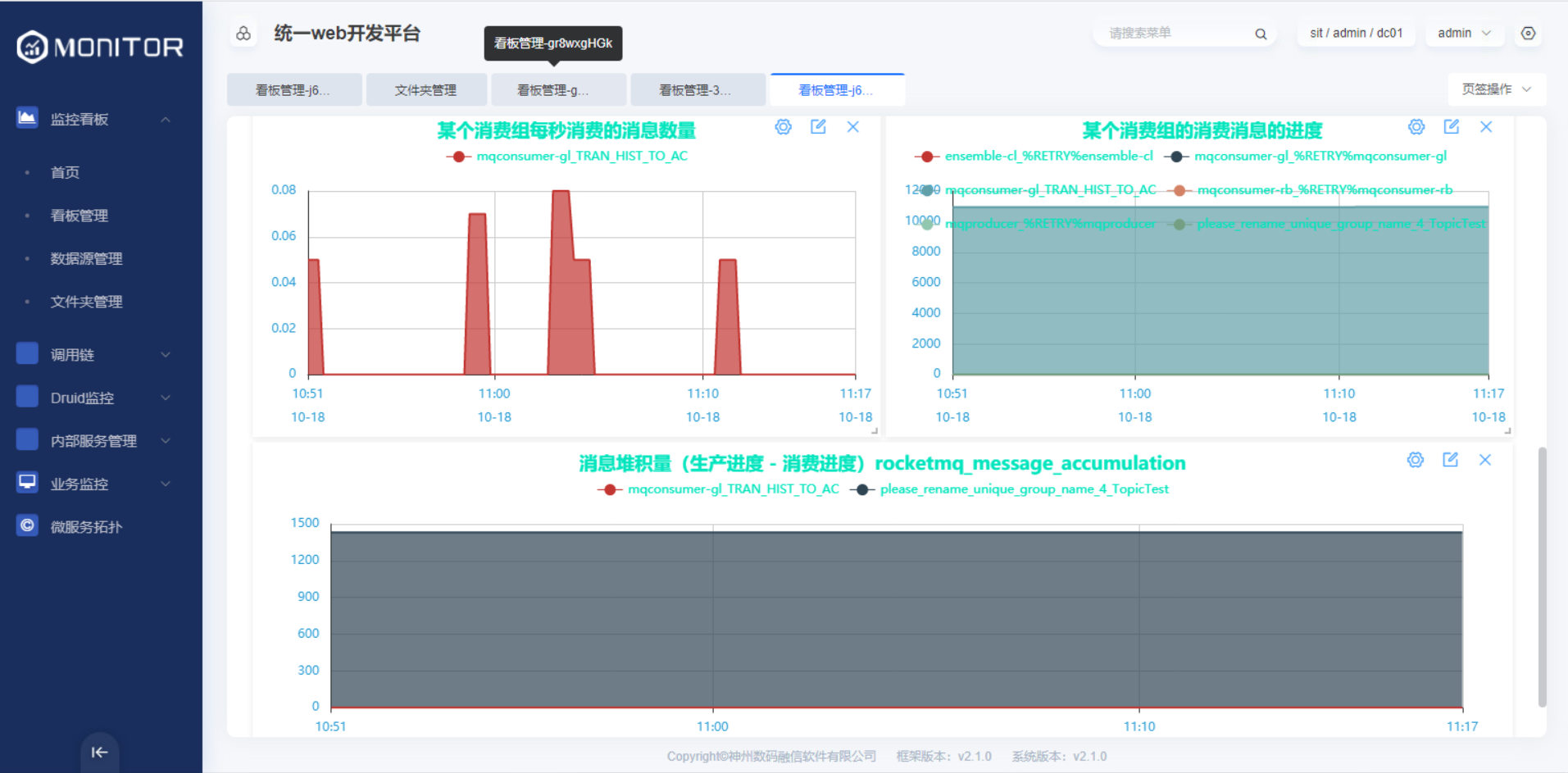
1.5.3.微服务JVM监控
微服务本身需要依赖micrometer-registry-prometheus.jar包
xml
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>1.5.3.1.prometheus配置:
将应用暴露的ip:port/actuator/prometheus端点参考下图配置到prometheus.yml配置文件中。多个节点使用逗号分隔。
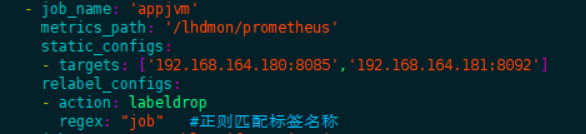
yaml
- job_name: 'appjvm'
metrics_path: '/lhdmon/prometheus'
static_configs:
- targets: [ '192.168.164.180:8085','192.168.164.181:8092' ]
relabel_configs:
- action: labeldrop
regex: "job" #正则匹配标签名称1.5.3.2.微服务JVM监控看板:
将prometheus/micro-server-monitor.json看板文件参考主机监控看板步骤导入。
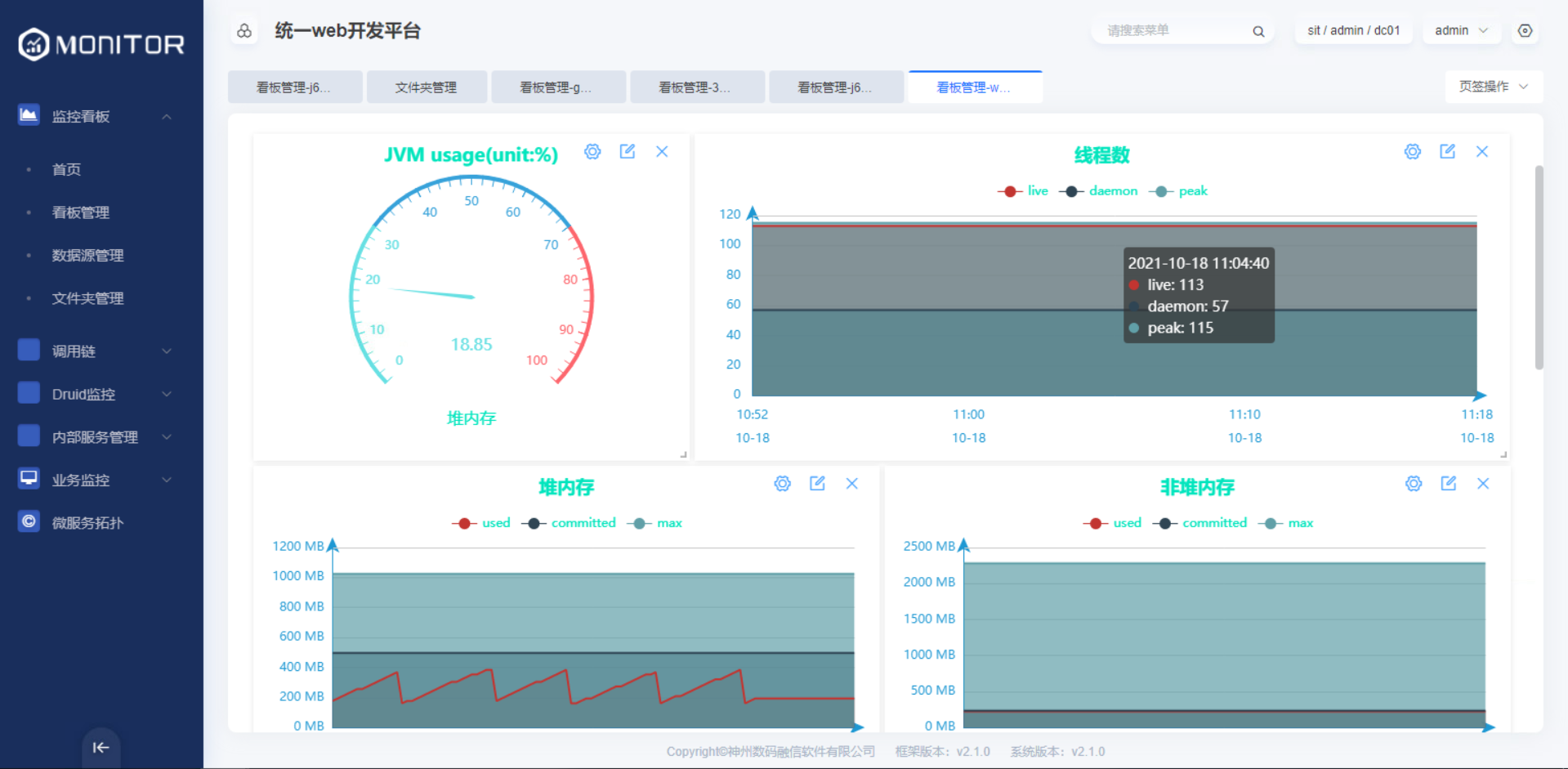
1.5.3.3.监控视图
1.6.看板文件导入
自aries-3.4.9版本后,提供俩套prometheus看板文件,分别是原生grafana看板文件,aries自有看板文件。

俩种看板文件监控内容一致,展示的图表不同。
注意:
使用原生grafana展示监控数据时候需要在auth的数据字典中配置原生grafana地址,配置如下图:
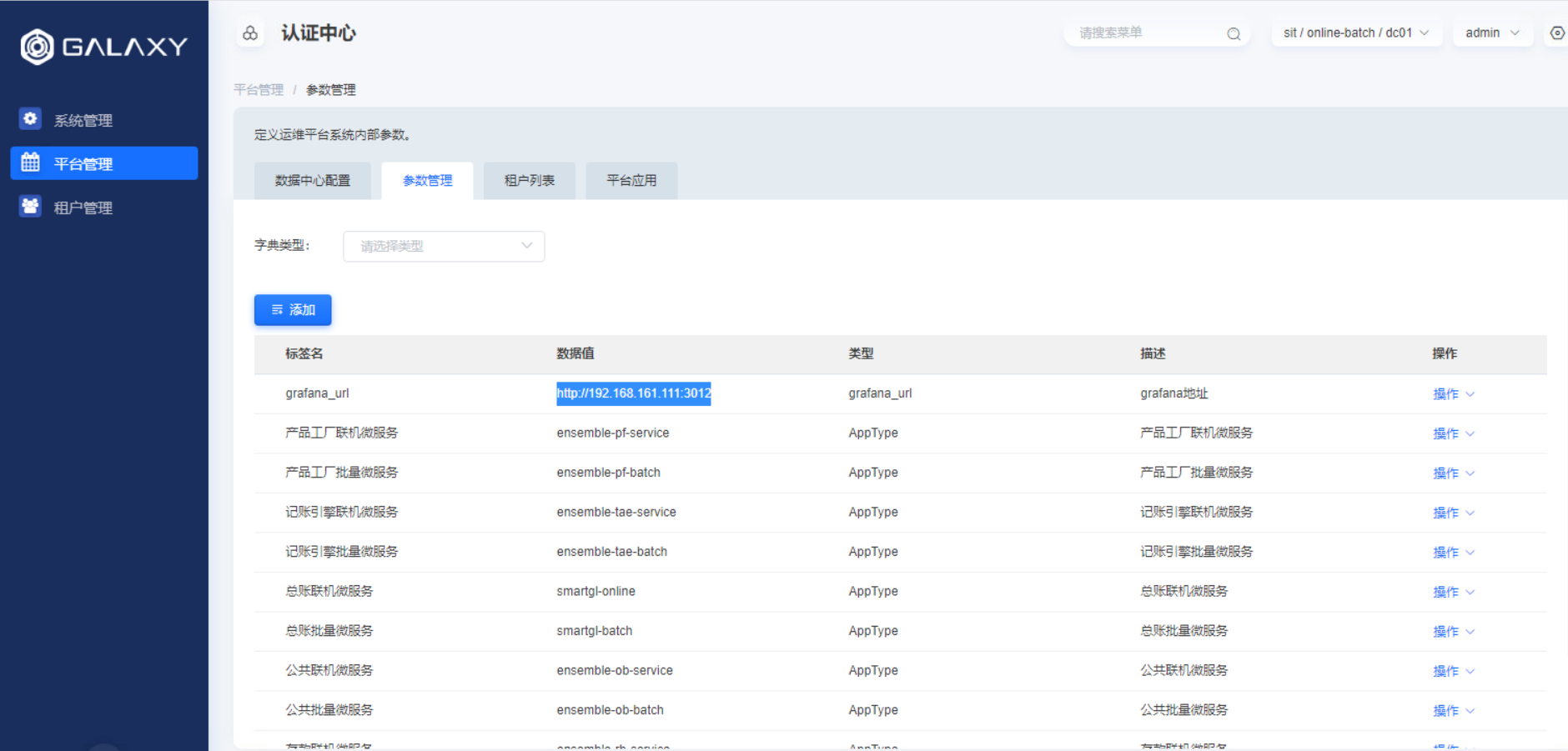
生产部署时,需要开通grafana所在服务器的3012端口。
以主机监控为例,导入看板步骤如下:
1、在添加数据源菜单创建prometheus数据源。
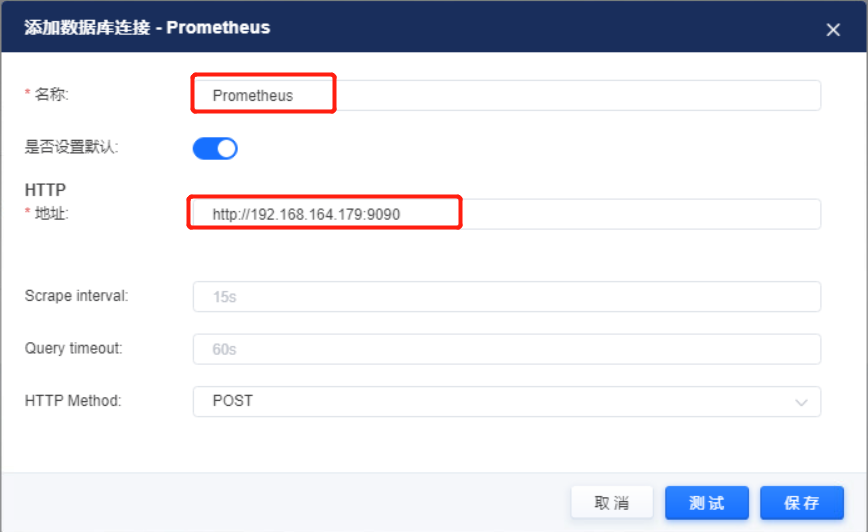
2、在文件夹管理菜单创建文件夹用于存放看板文件。
3、导入主机监控.json看板文件
4、导入后的主键监控界面