Appearance
Mars序列
1. 序列类型
Mars 目前支持四种类型的序列,不同类型的序列需要不同类型的序列生成器:
ORAS: Oracle 序列对象序列SNFS: 雪花算法序列DBTS: 基于数据库表的全局唯一序列DBGS: 基于数据库表的全局唯一连续自增序列
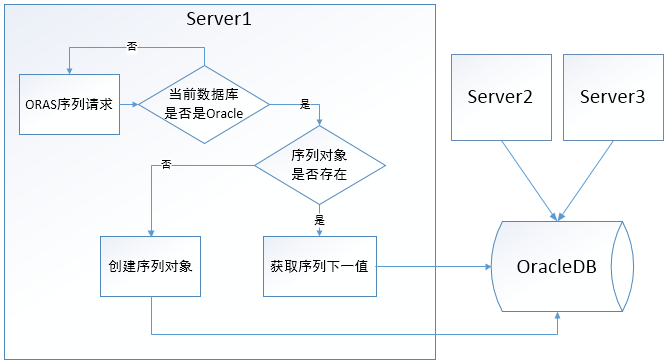
1.1 Oracle 序列对象序列(ORAS)
Oracle 序列对象序列是基于 Oracle 数据库序列对象所生成的序列,因此系统必须依赖 Oracle 数据库,方可利用该序列类型。
如下图所示,每个节点“地位”平等,都可以对外提供服务且处理流程逻辑一致。大概处理流程为:服务器节点收到请求后首先判断当前数据库是否为 Oracle 数据库,如果不是会抛出异常,如果是则判断所请求的序列名称是否存在,若不存在会新建该请求的序列。最后,获取序列值后返回给调用者。
1.2 雪花算法序列(SNFS)
雪花算法序列是基于标准雪花算法生成,如下图所示,其中 41bit 时间戳与标准雪花算法相同,10bit 是 IP:PORT 通过 hash 算法得到,12bit 与标准雪花算法不同,并不代表同一机器同一个毫秒内产生的不同 id,而是忽略机器差异,通过自动生成并进行自增得到。

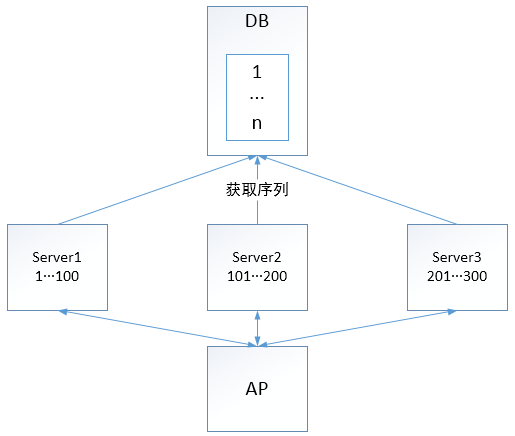
1.3 基于数据库表的全局唯一序列(DBTS)
基于数据库表的全局唯一序列,可以依赖任何数据库。其大概逻辑是如下图所示,每个服务器节点会缓存一定数量的序列号,所以客户端在获取序列的时候并非严格递增,也不会完全连续。可能会出现例如 1,101,2 等情况。
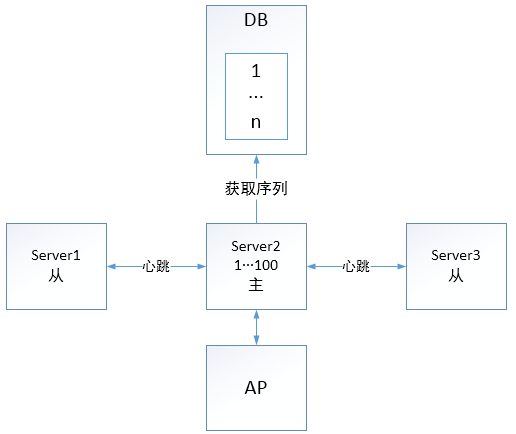
1.4 基于数据库表的全局唯一连续自增序列(DBGS)
基于数据库表的全局唯一连续自增序列,此种序列只能由主节点提供。主节点会缓存一段序列号。当缓存序列使用完后,再去数据库获取新的序列。如果请求错误的发送到从节点,从节点将直接返回指定错误。主节点与从节点之间通过心跳检查保持集群状态,当主节点出现问题,从节点会发起选举,选出新的主节点,继续对外提供服务。
但是该类型的序列也会存在问题,比如当 Mars 服务重启、主节点异常宕掉,当前缓存在主节点中尚未使用的序列就会丢失,当重启服务或重新选取出新的主节点时,会重新从数据库中获取一些序列号进行缓存,这种情况下,就会导致序列不连续,但是肯定保证唯一性。
2. 客户端集成
- jar 包依赖,pom.xml 中增加 Mars 依赖
xml
<dependency>
<groupId>com.dcits</groupId>
<artifactId>comet-sequence-galaxy-mars</artifactId>
</dependency>- 参数配置,application.yml 新增以下配置,Mars 如果是集群部署,多节点使用逗号分隔
yml
comet:
tenant:
appId: rb
profile: DEV
tenantId: online-batch
datacenter: dc01
sequence:
mars:
servers: dcits.mars.dc01:9004,dcits.mars.dc02:9004- 使用
新增序列类,继承 mars 提供的抽象类 AbstractGenerateSeq,编写构造方法,里面指定序列名称,最后调用 generateSeqNo() 即可实现序列的获取
示例:
java
public class DemoSeq extends AbstractGenerateSeq {
public DemoSeq() {
super("rb.demoSeq");
}
public String getSeqNo() {
return String.valueOf(generateSeqNo());
}
}3. Mars序列名称命名及使用规则
目前 Mars 服务对序列名称,在使用中有一些特殊处理,大致梳理了一下,仅供参考:
一般使用场景,序列名称就只是作为名称使用,比如
rb.reference高级用法,序列名称命名规范是:
<序列类型>_<模板ID>_<名称>或者<序列类型>_<名称>;
- 其中序列类型指的是 Oracle 序列对象 ORAS、雪花算法序列 SNFS、全局唯一序列 DBTS、全局唯一连续自增序列 DBGS;
- 特殊的一点是,序列类型还有一个特殊值,大写的
AUTO,该值与 DBGS 是一致的,表示该序列全局唯一连续自增; - 模板 ID,指的是在序列模板表
FW_SEQUENCES_MOULD中配置的模板信息,可为空,模板 ID 是纯数字类型,代码中有校验
- 在获取 Mars 值的时候,如果序列不存在,需要自动创建序列,优先从序列名称中截取序列类型,截取不到,再获取参数
sequences.server.autocreatetype配置的序列类型