Appearance
13 架构设计参考
13.1 数据拆分
数据拆分的终极目标是:保证数据分布尽可能的均匀,最终到各个分片节点的负载尽可能的均衡。具体的拆分过程可以从以下几个方面综合考虑:
- 具体的拆分方案需要对业务进行深入分析,如果一些表的数据量已经比较大,或者其的增长趋势比较明显,就要考虑进行分片。具体到什么量级需要分,跟后端对接的数据库有一定的关系,一般对于MySQL超过1000万就要拆分,如果是ORACLE或者DB2一般可以按3000~5000万(跟单节点的处理能力有关)考虑。
- 具体按什么字段进行拆分,需要对该表的常用WHERE条件进行分析。例如,如果80%以上的SQL(种类和使用率两个维度都要考虑)都是按客户号为条件进行操作的,那么就建议按客户号进行拆分,这样就会保证绝大多数关键的SQL都可以命中分片关键字,以保证其执行效率;而对其他一些使用率比较低的、不是很重要的SQL的处理速度就会稍慢。这也是分布式体系中的取舍之道。
- 具体的分片算法跟分片键的业务属性(主要考虑增长特性及数据分散的规律)有一定关系。例如,如果是一个日期类型的字段作为分片键,就可以按照其数据量的实际情况,决定是按月份或者日期的算法进行拆分;如果是客户号就可以按照其全部或者部分信息的后几位进行取余,或者Hash等方式。
- 具体分多少片需要跟结合现在的数据量,以及未来的增长趋势综合来考虑,同时还要考虑日常运维及扩容的复杂度。分的太少,经常性的扩容,风险较高,并且运维的压力也大;分的太多,日常的运维管理工作也会相对增加,并且也浪费资源,甚至不仅不能提升性能,反而还会降低性能。
- 为了尽可能的减少跨分片的JOIN,对一些跟上述分片表有一定关联关系,并且经常进行JOIN查询的表,尽量配置成其的ER关系子表,这样其就可以通过关联字段跟分片表保持相同的分片策略。单独查这些表的时候,只要查询条件中包括关联字段,其就可以通过ER关系间接的到具体分片中查询,以提升查询效率;如果跟主分片表通过ER关联字段JOIN查询时,就可以在一个分片中查询。
- 对于小表(数据量不大,如千万以下),尽量不要配置成拆分表。如果表比较独立,与其他的表基本上不进行JOIN运算,可以作为非拆分表处理,性能不能满足要求的时候可以通过配置读写分离机制来提高性能。如果需要与拆分表进行JOIN运算,可以配置成全局表。
13.2 数据扩容
当数据存储能力或者计算能力无法支持生产级要求时,在集中式数据库中一般都是采用增加数据库的硬件资源来实现的,也就是垂直扩展的模式,但随着数据量及交易量的不断攀升,增加数据库的硬件资源不仅成本急剧上升,而且数据库的物理资源也是有上限的,到一定程度就无法再增加了。在分布式体系下,则更多的是采用增加机器的方式来实现的,也就是水平扩展的模式。
扩容机制大的有 按需扩展 和 提前规划 两种模式;
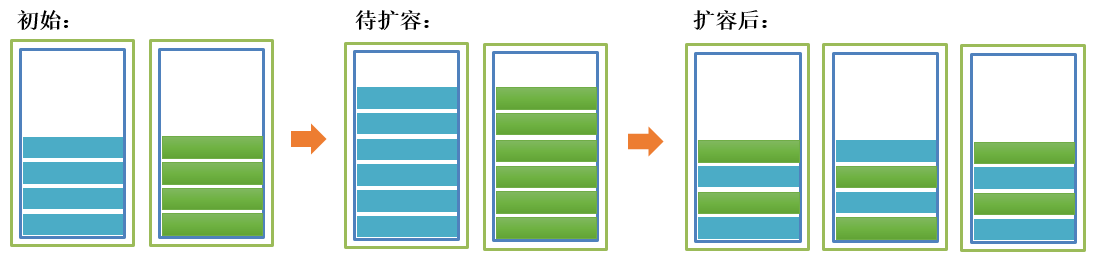
按需扩展:也就是目前的节点数只保证现有的数据量和计算能力,如果不能满足的时候再增加节点,同时调整分片规则,将数据重新分片到所有节点。这种模式因为参与节点数的变化,间接的造成分片规则的变化,所以肯定要面临数据迁移,迁移的量跟具体的算法关系紧密。但由于初期的节点数相对较少,运维的日常维护工作要少。如下图所示:
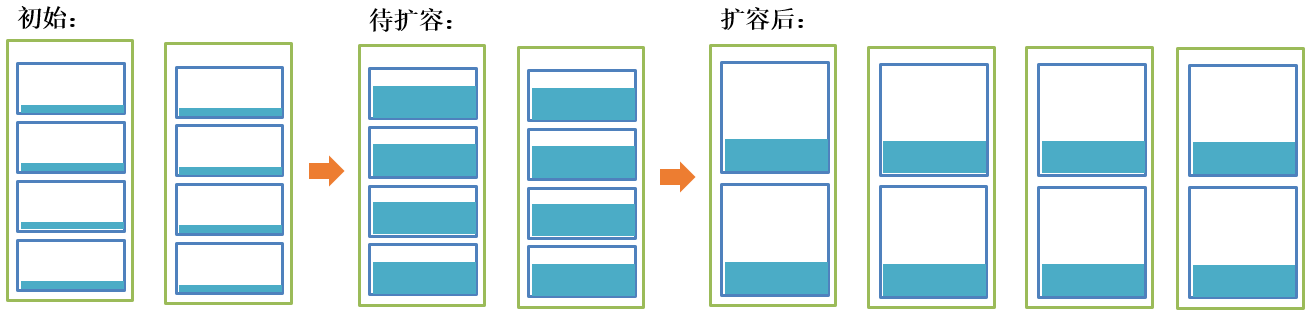
提前规划:提前对系统的数据容量进行规划,然后再预留一定的余量,然后按这个数据量规划总共要分多少片,但考虑到初期的数据量还比较少,分配过多的数据库就会造成明显的浪费,所以,可以一个物理库承担多个分片,以MySQL为例,某台物理机上安装了一个MySQL实例,该MySQL实例有包括4个database,每一个分片对应一个database,也就是4个分片在逻辑上是分离的,但物理上公用一个MySQL实例对应的物理资源;如果后续数据量增加到一定程度,单个MySQL实例的压力已经很大了,就可以增加另外的MySQL实例,然后将其中的某些database迁移到新的MySQL实例上,这样整体的数据库运行资源就会增加,每个节点可使用的物理资源也明显增加。该种模式最大的优势就是由于分片数量提前规划好,后续扩容的过程,只是某个分片的整体搬迁,并不会带来大规模的表内部数据的迁移,运维复杂度大幅度降低。但由于提前规划,所以扩容的最大物理库的数量等于分片数量,也就是一个分片节点独占一个物理库。如下图所示:
上述两种扩容策略并不是完全对立的,我们建议优先按提前规划的模式,如果确实超出了规划的容量,再结合按需扩展的模式,甚至适当的时候也可以有限的使用垂直扩容的模式。
13.3 物理资源评估
首先需要考虑的就是磁盘的容量大小,其需要综合考虑,而不仅仅考虑数据存储所需的容量。上述两种模式在这个层面上差别不大,主要是一个考虑的是规划的总数据量,一个是当前支持的数据量。但都需要对业务数据所占的磁盘容量进行估算,然后每个物理库的磁盘容量应该至少应该: $$ 所需磁盘容量 = 总数据容量/分片数 + 系统所用磁盘 + 磁盘备份所需的磁盘 + 其他功能所需磁盘 $$ 具体的估算方式,可以按照主要业务表中的所有列的最大值进行累加(考虑到一些字符类型的字段设置过长,大部分情况下都较短,可以再乘上一定的系数),可以算出每一行数据的最大字节数,然后再乘以预计的行数,基本就可以估算出大致的容量,建议再增加一定的余量。
对于CPU和内存建议结合系统所需的处理能力及并发度的情况进行实际压测,再根据压测结果进行调整。
分布式体系下对网络的依赖比较大,所以网络必须至少是稳定的千兆网以上。 就是自定义的扩展实现。